Paramètres du cluster 1s 8.3
Hier encore, nous avons mis à jour tous les logiciels serveur. Abordons peut-être les fonctionnalités les plus intéressantes et les nouvelles du cluster de serveurs 1C:Enterprise 8.3.
Vous pouvez voir comment configurer un cluster de serveurs pour 1C:Enterprise 8.2 dans la section précédente. Je ne m'attarderai pas sur certains points ; ils ont déjà été décrits précédemment.
ALORS, CE QUI A CHANGÉ DANS LE CLUSTER 1C:Enterprise 8.3 :
Tout d'abord, après avoir installé le cluster 1C:Enterprise 8.3, il a fallu créer des workflows. Il s'avère que les processus de cluster sont désormais créés automatiquement en fonction de la charge sur le système comptable.
Un essai de tâches en arrière-plan de la base de données principale a provoqué une surcharge sans fin du cluster 1C:Enterprise 8.3. rphost.exe et supplémentaire rphost.exe Je ne voulais pas être créé. Après avoir fouillé dans les paramètres, tout est devenu clair.

Mémoire de flux de travail maximale est la quantité de mémoire que les processus de travail peuvent utiliser ensemble. Vous devez être très prudent lors du réglage du paramètre, mesuré en octets. Si vous définissez une valeur incorrecte (insuffisante pour le fonctionnement normal de l'utilisateur), les utilisateurs recevront l'erreur « Il n'y a pas assez de mémoire libre sur le serveur 1C:Enterprise ». Vous pouvez également obtenir cette erreur lorsque le quota de mémoire sur le serveur 1C:Enterprise est épuisé.
Consommation de mémoire sécurisée par appel- permet de contrôler la consommation mémoire lors d'un appel serveur, mesurée en octets. Si un appel utilise plus de mémoire que prévu, cet appel sera terminé au sein du cluster 1C sans redémarrer le processus de travail ( rphost.exe). En conséquence, le « perdant » qui a appelé le serveur perdra sa session avec la base de données sans affecter le travail des autres utilisateurs.
La quantité de mémoire de processus de travail jusqu'à laquelle le serveur est considéré comme productif- si ce paramètre est dépassé, le serveur du cluster 1C:Enterprise 8.3 cessera d'accepter de nouvelles connexions.
Nombre de sécurité des informations par processus- vous permet d'isoler les bases d'informations pour les processus de travail. Par défaut, le cluster 1C:Enterprise 8.3 actuel était défini sur « 8 », mais pendant plusieurs heures, le serveur s'est comporté de manière instable et les sessions utilisateur se sont figées. Après avoir isolé chaque infobase (valeur - « 1 »), les problèmes ont disparu.
Nombre de connexions par processus- la valeur par défaut est « 128 ». Étant donné que la base de données actuelle comporte une très grande charge de tâches de fond (calculs logistiques, analyse des listes de prix, analyse des concurrents, etc.), il a été décidé de réduire ce nombre à « 25 ».
Les paramètres du cluster 1C:Enterprise 8.3 lui-même ont légèrement changé :

Niveau de tolérance aux pannes- c'est le nombre de serveurs fonctionnels qui peuvent tomber en panne en même temps, et cela n'entraînera pas de licenciement anormal des utilisateurs. Les services de sauvegarde sont lancés automatiquement dans la quantité nécessaire pour garantir la tolérance aux pannes spécifiée. En temps réel, le service actif est répliqué vers ceux de sauvegarde.
Mode de partage de charge- il existe deux options pour le paramètre : « Priorité par performances » - plus de mémoire du serveur est dépensée et les performances sont plus élevées, « Priorité par mémoire » - le cluster « 1C : Enterprise 8.3 » économise la mémoire du serveur.
Au lieu d'une postface. Le cluster 1C:Enterprise 8.3 fonctionne sensiblement plus rapidement et de manière plus fiable, la création d'une session utilisateur avec une base d'informations est plusieurs fois plus rapide, l'interface en mode compatibilité avec 1C:Enterprise 8.2.16, pourrait-on dire, vole. Bien sûr, il y a des nuances, mais que serions-nous sans elles ? Bonne chance dans la configuration du nouveau cluster 1C:Enterprise 8.3.
Le serveur 8.3 se caractérise par un code interne nouvellement repensé, même si « de l'extérieur » il peut sembler qu'il s'agit d'un 8.2 légèrement modifié.
Le serveur est devenu plus « auto-configurable » ; certains paramètres, comme le nombre de processus de travail, ne sont plus créés manuellement, mais sont calculés sur la base des descriptions des exigences de tolérance aux pannes et des tâches de fiabilité.
Un mécanisme d'équilibrage de charge a été développé, qui peut être utilisé soit pour augmenter les performances du système dans son ensemble, soit pour utiliser un nouveau mode « économie de mémoire », qui permet de travailler « avec une mémoire limitée » dans les cas où la configuration utilisé « aime manger de la mémoire ».

La stabilité de fonctionnement lors de l'utilisation de grandes quantités de mémoire sera déterminée par les nouveaux paramètres du serveur de production.

Le paramètre « Consommation de mémoire sécurisée par appel » est particulièrement intéressant. Pour ceux qui n’ont aucune idée de ce que c’est, mieux vaut ne pas s’entraîner sur une base « productive ». Le paramètre "Taille mémoire maximale des processus de travail" permet, en cas de "débordement", de ne pas planter l'ensemble du processus de travail, mais une seule session "avec le perdant". « La quantité de mémoire pour les processus de travail jusqu'à laquelle le serveur est considéré comme productif » permet de bloquer les nouvelles connexions dès que ce seuil de mémoire est dépassé.
Je recommande d'isoler les processus de travail par base d'informations, par exemple en précisant le paramètre « Nombre d'informations de sécurité par processus = 1 ». Avec plusieurs bases de données très chargées, cela réduira l’influence mutuelle en termes de fiabilité et de performances.
Une contribution distincte à la stabilité du système est apportée par les « dépenses » de licences/clés. En 8.3, il est devenu possible d'utiliser un « gestionnaire de licences logicielles », rappelant le gestionnaire « aladin ». Le but est de pouvoir placer la clé sur une machine distincte.
Il est implémenté comme un autre « service » dans le gestionnaire de cluster. Vous pouvez utiliser, par exemple, un ordinateur portable « gratuit ». Ajoutez-le au cluster 1C 8.3, créez-y un gestionnaire distinct avec le service « service de licences ». Vous pouvez insérer une clé matérielle dans votre ordinateur portable ou activer des licences logicielles.
Les « exigences d’affectation des fonctionnalités » devraient être les plus intéressantes pour les programmeurs.

Ainsi, sur un ordinateur portable doté d'une clé de sécurité, afin de ne pas lancer d'utilisateurs sur le serveur de cluster, vous devez ajouter des « exigences » pour l'objet d'exigence « Connexion client à la sécurité des informations » - « Ne pas attribuer », c'est-à-dire empêcher les processus de travail sur ce serveur de traiter les connexions client.
Encore plus intéressante est la possibilité d’exécuter des « tâches en arrière-plan uniquement » sur le serveur de production du cluster sans sessions utilisateur. De cette façon, vous pouvez déplacer des tâches très chargées (code) vers une machine distincte. De plus, vous pouvez exécuter une tâche en arrière-plan de « clôture du mois » en utilisant la « Valeur d'un paramètre supplémentaire » sur un ordinateur, et la tâche en arrière-plan « Mise à jour de l'index de texte intégral » sur un autre s'effectue via l'indication « Valeur de ». un paramètre supplémentaire ». Par exemple, si vous spécifiez BackgroundJob.CommonModule comme valeur, vous pouvez limiter le travail du serveur de travail dans le cluster aux seules tâches en arrière-plan avec n'importe quel contenu. La valeur BackgroundJob.CommonModule..- indiquera le code spécifique.
Il est clair qu'il ne sert à rien de raconter la documentation. Mais si quelqu'un donne des conseils utiles, je développerai l'article.
Tout d'abord, après avoir installé le cluster 1C, il a fallu créer des workflows. Il s'est avéré que les processus de cluster ont commencé à être créés automatiquement en fonction de la charge de la base de données.
Un test de tâches en arrière-plan de la base de données principale a provoqué une surcharge infinie du cluster 1C sur rphost.exe et le rphost.exe supplémentaire n'a pas voulu être créé. Après avoir fouillé dans les paramètres, tout est devenu clair.
Mémoire de flux de travail maximale est la quantité de mémoire que les processus de travail peuvent utiliser ensemble. Vous devez être très prudent lors de la définition du paramètre, mesuré en octets. Si vous définissez une valeur incorrecte (insuffisante pour le fonctionnement normal de l'utilisateur), les utilisateurs recevront l'erreur « Pas assez de mémoire libre sur le serveur 1C ». Vous pouvez également obtenir cette erreur lorsque le quota de mémoire sur le serveur 1C est épuisé.
Consommation de mémoire sécurisée par appel– permet de contrôler la consommation de mémoire lors d’un appel serveur, mesurée en octets. Si un appel utilise plus de mémoire que prévu, cet appel sera terminé au sein du cluster 1C sans redémarrer le processus de travail (rphost.exe). En conséquence, le « perdant » qui a appelé le serveur perdra sa session avec la base de données 1C sans affecter le travail des autres utilisateurs.
dans un Go – 1073741824 octets, donc dans 2 Go – 2147483648 octets
La quantité de mémoire pour les processus de travail jusqu'à laquelle le serveur est considéré comme productif - si ce paramètre est dépassé, le serveur du cluster 1C cessera d'accepter de nouvelles connexions.
Nombre de sécurité des informations par processus– vous permet d'isoler les bases d'informations pour les processus de travail. Par défaut, le cluster 1C actuel était défini sur « 8 », mais au cours de plusieurs heures de fonctionnement, le serveur s'est comporté de manière très instable, les sessions des utilisateurs se sont figées. Après avoir isolé chaque infobase (valeur – « 1 »), les problèmes ont disparu.
Nombre de connexions par processus- valeur par défaut " 128 « . Étant donné que la base de données actuelle comporte une très grande charge de tâches de fond (calculs logistiques, analyse des listes de prix, analyse des concurrents, etc.), il a été décidé de réduire ce nombre à « 25 ».
Les paramètres du cluster 1C lui-même ont légèrement changé :

Niveau de tolérance aux pannes– c'est le nombre de serveurs fonctionnels qui peuvent tomber en panne simultanément, et cela n'entraînera pas de licenciement anormal des utilisateurs. Les services de sauvegarde sont lancés automatiquement dans la quantité nécessaire pour garantir la tolérance aux pannes spécifiée. En temps réel, le service actif est répliqué vers ceux de sauvegarde.
Mode de partage de charge– il existe deux options pour le paramètre : « Priorité par performance » – plus de mémoire du serveur est dépensée et les performances sont plus élevées, « Priorité par mémoire » – le cluster 1C économise la mémoire du serveur.
Le serveur 8.3 se caractérise par un code interne nouvellement repensé, même si « de l'extérieur » il peut sembler qu'il s'agit d'un 8.2 légèrement modifié.
Le serveur est devenu plus « auto-configurable » ; certains paramètres, comme le nombre de processus de travail, ne sont plus créés manuellement, mais sont calculés sur la base des descriptions des exigences de tolérance aux pannes et des tâches de fiabilité.
Cela réduit le risque de mauvaise configuration du serveur et abaisse les exigences de qualification des administrateurs.
Un mécanisme d'équilibrage de charge a été développé, qui peut être utilisé soit pour augmenter les performances du système dans son ensemble, soit pour utiliser un nouveau mode « économie de mémoire », qui permet de travailler « avec une mémoire limitée » dans les cas où la configuration utilisé « aime manger de la mémoire ».
La stabilité de fonctionnement lors de l'utilisation de grandes quantités de mémoire sera déterminée par les nouveaux paramètres du serveur de production.
Le paramètre « Consommation de mémoire sécurisée par appel » est particulièrement intéressant. Pour ceux qui n’ont aucune idée de ce que c’est, mieux vaut ne pas s’entraîner sur une base « productive ». Le paramètre « Taille maximale de la mémoire des processus de travail » permet, en cas de « débordement », de ne pas planter l'ensemble du processus de travail, mais une seule session « avec le perdant ». « La quantité de mémoire de processus de travail jusqu'à laquelle le serveur est considéré comme productif » permet de bloquer les nouvelles connexions dès que ce seuil de mémoire est dépassé.
Je recommande d'isoler les processus de travail par base d'informations, par exemple en précisant le paramètre « Nombre d'informations de sécurité par processus = 1 ». Avec plusieurs bases de données très chargées, cela réduira l’influence mutuelle en termes de fiabilité et de performances.
Une contribution distincte à la stabilité du système est apportée par les « dépenses » de licences/clés. En 8.3, il est devenu possible d'utiliser un « gestionnaire de licences logicielles », rappelant le gestionnaire « aladin ». Le but est de pouvoir placer la clé sur une machine distincte.
Il est implémenté comme un autre « service » dans le gestionnaire de cluster. Vous pouvez utiliser, par exemple, un ordinateur portable « gratuit ». Ajoutez-le au cluster 1C 8.3, créez-y un gestionnaire distinct avec le service « service de licences ». Vous pouvez insérer une clé matérielle dans votre ordinateur portable ou activer des licences logicielles.
Les « exigences d’affectation des fonctionnalités » devraient être les plus intéressantes pour les programmeurs.
Exigences pour la fonctionnalité attribuée de 1c
Ainsi, sur un ordinateur portable doté d'une clé de sécurité, afin de ne pas lancer d'utilisateurs sur le serveur du cluster, vous devez ajouter des « exigences » pour l'objet d'exigence « Connexion client à la sécurité des informations » – « Ne pas attribuer », c'est-à-dire empêcher les processus de travail sur ce serveur de traiter les connexions client.
La possibilité d'exécuter des « tâches en arrière-plan uniquement » sur le serveur de production du cluster sans sessions utilisateur est encore plus intéressante. De cette manière, les tâches très chargées (code) peuvent être transférées vers une machine distincte. De plus, vous pouvez exécuter une tâche en arrière-plan de « clôture du mois » en utilisant la « Valeur d'un paramètre supplémentaire » sur un ordinateur, et la tâche en arrière-plan « Mise à jour de l'index de texte intégral » sur un autre s'effectue via l'indication « Valeur de ». un paramètre supplémentaire ». Par exemple, si vous spécifiez BackgroundJob.CommonModule comme valeur, vous pouvez limiter le travail du serveur de travail dans le cluster aux seules tâches en arrière-plan avec n'importe quel contenu. Valeur BackgroundJob.CommonModule.<Имя модуля>.<Имя метода>– indiquera un code spécifique.
En plus de la version fichier, le système 1C:Enterprise peut fonctionner avec des bases d'informations dans une version client-serveur. Dans ce dernier cas, on entend une architecture composée de plusieurs couches logicielles, schématiquement représentées dans la figure ci-dessous.
- Applications clientes, clients légers et clients Web- il s'agit de « 1C:Enterprise » dans différents modes de lancement avec lesquels travaille l'utilisateur final. Pour les applications clientes et les clients légers, un navigateur web suffit sur les ordinateurs des utilisateurs (ou sur), pour un client web.
- Cluster de serveurs "1C:Entreprise" est un ensemble de processus de travail exécutés sur un ou plusieurs ordinateurs et une liste de bases d'informations situées dans ce cluster. Dans le cluster de serveurs, tout le travail des objets d'application est effectué, des préparations sont effectuées pour l'affichage des formulaires (lecture des objets de la base d'informations, remplissage des données du formulaire, organisation des éléments, etc.) et de l'interface de commande, génération de rapports et exécution de tâches en arrière-plan. Les clients affichent uniquement les informations préparées dans le cluster de serveurs. De plus, les fichiers de service sont stockés sur le serveur du cluster 1C:Enterprise, ainsi qu'un journal d'enregistrement de la base d'informations.
- Serveur de base de données— sur le serveur de base de données, le stockage direct et le travail avec les données ont lieu, assurés par l'un des systèmes de gestion de base de données (SGBD) suivants pris en charge par le système 1C:Enterprise :
- Microsoft SQL Server à partir de Microsoft SQL Server 2000 et versions ultérieures ;
- PostgrageSQL depuis la version 8.1 ;
- IBM DB2 depuis la version 9.1 ;
- Base de données Oracle depuis la version 10g Release 2.
- serveur Web requis uniquement pour les clients Web et l'une des options de client léger. Fournit une interaction de ces types de connexions avec un cluster de serveurs 1C:Enterprise.
Il convient également de noter que chaque couche logicielle ne doit pas nécessairement être située sur un ordinateur physique distinct. Un cluster de serveurs peut être situé sur le même ordinateur qu'un serveur de base de données, un serveur Web, etc. Par exemple, la structure de travail suivante se retrouve souvent dans les petites organisations :

Dans cet article, je vais décrire l'installation du serveur 1C:Enterprise version 8.3.4.389 (pour les autres versions de la plateforme 1C:Enterprise 8.1, 8.2 et 8.3 les étapes sont similaires) sur un ordinateur exécutant Windows Server 2008 (R2) ou Windows Serveur 2012 (R2). Microsoft SQL Server 2008 (R2) ou Microsoft SQL Server 2012 seront considérés comme un SGBD. Pour cela nous aurons besoin de :
- Un ordinateur qui répond à la configuration système requise pour l'installation du serveur 1C:Enterprise et avec le système d'exploitation installé sur cet ordinateur ou .
- Un ordinateur pour un serveur de base de données, exécutant également un système d'exploitation ou (peut être l'ordinateur de l'étape 1).
- Droits d'administrateur local sur les deux ordinateurs.
- Kit de distribution pour l'installation du serveur 1C:Enterprise 8.
- Licence logicielle ou clé de protection HASP4 Net pour le serveur 1C:Enterprise.
- Kit de distribution pour l'installation de Microsoft SQL Server 2008 (R2) ou Microsoft SQL Server 2012.
2. Installation du SGBD MS SQL Server
Nous installons le SGBD MS SQL Server sur l'ordinateur qui sert de serveur de base de données. Pour faire fonctionner le système 1C:Enterprise, il suffit d'installer les composants suivants :
- Services de moteur de base de données
- Outils de gestion – Basique
- Outils de gestion - Complets.
Sélectionnez les options de tri " Cyrillique_Général_CI_AS" Détails sur l'installation des systèmes
3. Configuration du pare-feu Windows pour le fonctionnement du SGBD
Si le serveur de base de données et le serveur de cluster 1C:Enterprise sont situés sur des ordinateurs physiques différents, vous devez configurer le pare-feu Windows sur le serveur de base de données afin que le serveur 1C:Enterprise puisse fonctionner avec le SGBD, à savoir ouvrir les connexions entrantes sur le port. 1433 (pour l'instance SQL Server par défaut).
- J'ai écrit en détail sur la configuration du pare-feu Windows pour Microsoft SQL Server 2008 (R2) / 2012.
4. Ajout d'un utilisateur à MS SQL Server
Ensuite, nous ajouterons un utilisateur distinct à MS SQL Server, sous lequel les bases de données du serveur 1C:Enterprise seront connectées. Cet utilisateur sera également propriétaire de ces bases de données. L'utilisateur à ajouter doit être autorisé sur le serveur à l'aide d'un mot de passe et disposer de l'ensemble de rôles suivant : créateur de base de données, administrateur de processus, publique. Détails sur l'ajout d'un utilisateur à
- Microsoft SQL Server 2008 (R2) que j'ai écrit.
- J'ai écrit Microsoft SQL Server 2012.
5. Installation du serveur 1C:Enterprise
Passons maintenant à l'installation des fichiers du serveur 1C:Enterprise et au démarrage du service correspondant. L'installation nécessite un kit de distribution de la plateforme technologique 1C:Enterprise. Dans la liste des distributions fournies, les suivantes conviennent :
- Plateforme technologique 1C:Enterprise pour Windows - permet l'installation d'un serveur 1C:Enterprise 32 bits
- Serveur 1C:Enterprise (64 bits) pour Windows - permet l'installation de serveurs 1C:Enterprise 32 bits et 64 bits
(Il existe également une version étendue du serveur KORP 1C:Enterprise 8.3, les détails peuvent être trouvés sur le site Web de 1C)
Ouvrez le répertoire contenant les fichiers d'installation du serveur 1C:Enterprise et exécutez le fichier setup.exe.

L'assistant d'installation du système 1C:Enterprise démarrera. Sur la première page cliquez sur " Plus loin».

Sur la page suivante, vous devez sélectionner les composants qui seront installés ; nous avons besoin des composants suivants :
- Serveur 1C : Entreprise— 1C : composants du serveur d'entreprise
- Administration du serveur 1C:Entreprise 8— composants supplémentaires pour administrer un cluster de serveurs 1C:Enterprise
Les composants restants (la liste des composants peut dépendre de la distribution spécifique), selon les besoins, peuvent également être installés sur cet ordinateur. Après avoir fait votre choix, cliquez sur « Plus loin».

Sélectionnez la langue de l'interface qui sera utilisée par défaut et cliquez sur " Plus loin».

Si le serveur 1C:Enterprise est installé en tant que service Windows (et dans la plupart des cas, il doit être installé en tant que tel), je recommande de créer immédiatement un utilisateur distinct sous lequel le service créé sera lancé. Pour ça
- Laissez le drapeau "on" Installez le serveur 1C:Enterprise en tant que service Windows (recommandé)»;
- On déplace le switch correspondant sur « Créer un utilisateur USR1CV8».
- Saisissez deux fois le mot de passe de l'utilisateur en cours de création. Par défaut, le mot de passe doit être conforme à la politique de mot de passe Windows. Vous pouvez en savoir plus à ce sujet :
- Pour Microsoft Windows Server 2008 (R2) - ;
- Pour Microsoft Windows Server 2012 - .
Vous pouvez également sélectionner un utilisateur existant pour exécuter le serveur 1C:Enterprise. Dans ce cas, l'utilisateur sélectionné doit disposer des droits suivants :
- Connectez-vous en tant que service
- Connectez-vous en tant que travail par lots
- Utilisateurs du journal de performances.
De plus, l'utilisateur doit disposer des droits nécessaires sur le répertoire des fichiers de service du serveur (par défaut C:\Program Files\1cv8\srvinfo pour 64 bits et C:\Program Files (x86)\1cv8\srvinfo pour un serveur 32 bits).
Utilisateur créé automatiquement USR1CV8 aura tous les droits ci-dessus.
Après avoir renseigné les paramètres appropriés, cliquez sur " Plus loin».

Et enfin, cliquez sur « Installer» pour démarrer l'installation. Cela copiera les fichiers des composants sélectionnés, créera des fichiers de configuration, enregistrera les composants du programme, créera des raccourcis et démarrera également le service serveur 1C:Enterprise.

Une fois l'installation terminée, l'assistant vous demandera d'installer le pilote de protection - HASP Device Driver. Si vous utilisez une licence logicielle pour le serveur 1C:Enterprise, il n'est pas nécessaire d'installer le pilote. Laisser ou supprimer le drapeau " Installer le pilote de protection" et cliquez sur " Plus loin».
|
Louer 1C:ERP Solution cloud |
Gestion des livraisons Pour les entreprises de commerce et de messagerie ! |
1C:EDO Découvrez tous les avantages de la gestion électronique de documents ! |
Fin du support |
Louer un serveur 1C |



Cluster de serveurs 1C - création de systèmes à forte charge
Commander une démonstration CommanderCet article examinera plusieurs options pour la structure 1C pour les systèmes à forte charge (à partir de 200 utilisateurs actifs) construits sur la base d'une architecture client-serveur - leurs avantages et inconvénients, les coûts d'installation et les tests de performances comparatifs de chaque option.
Nous ne décrirons pas, n'évaluerons pas et ne comparerons pas les schémas classiques généralement acceptés et connus de longue date pour construire une structure de serveur 1C, tels qu'un serveur 1C séparé et un serveur SGBD séparé, ou un cluster Microsoft SQL avec un cluster 1C. Il existe un grand nombre d’analyses de ce type, y compris celles menées par les fabricants de produits logiciels eux-mêmes. Nous vous proposerons un aperçu des schémas de conception de structure 1C rencontrés ces dernières années dans nos projets informatiques pour les moyennes et grandes entreprises.
Exigences pour les systèmes 1C hautement chargés
Les systèmes 1C très chargés fonctionnant avec de grandes quantités de données 24 heures sur 24, 7 jours sur 7 et 365 jours par an, sont soumis à des facteurs de risque qui ne sont généralement pas observés dans des situations standard. En conséquence, pour les éliminer et les prévenir, l'utilisation de schémas d'architecture 1C spéciaux et de nouvelles technologies est nécessaire.
Résistance aux catastrophes des SGBD. Dans le processus de conception de l'architecture 1C, l'accent est mis sur la puissance de calcul et la haute disponibilité des services, exprimées dans leur clustering. Par défaut, les serveurs 1C:Enterprise sont capables de fonctionner dans un cluster redondant, et pour un cluster SGBD, un système de stockage de données industriel (SDS) et une technologie de clustering (par exemple, Microsoft SQL Cluster) sont généralement utilisés. Cependant, la situation devient désastreuse lorsque des problèmes surviennent avec le système de stockage lui-même (souvent, d'après notre expérience de ces dernières années, il s'agit de problèmes logiciels). L'ingénieur informatique est alors soudainement confronté à deux problèmes : où obtenir des données à jour et où les déployer dans les plus brefs délais, puisqu'un système de stockage de données avec le volume requis d'une baie de disques rapide n'est pas disponible.
Exigences de sécurité de la base de données. En travaillant avec des projets de moyennes et grandes entreprises, nous sommes régulièrement confrontés à des exigences en matière de protection des données personnelles (en particulier pour nous conformer aux paragraphes de la loi fédérale 152). L'une des conditions pour répondre à ces exigences est d'assurer une bonne sécurité des données personnelles, ce qui nécessite le cryptage de la base de données 1C.
Lors du développement d'un schéma pour des systèmes 1C à forte charge, les gens font généralement attention en premier lieu aux paramètres du système d'entrée/sortie de disque sur lequel se trouvent les bases de données. Mais à côté de cela, il existe également une utilisation active des ressources CPU et de la consommation de RAM par le serveur 1C. Souvent, c'est précisément ce type de ressources qui manque ; les possibilités de mises à niveau matérielles du serveur 1C actuel sont épuisées et il est nécessaire d'ajouter de nouveaux serveurs 1C fonctionnant avec un seul serveur SGBD.Schémas d'organisation de clusters de serveurs 1C
Schéma avec un cluster de serveurs 1C connectés à un cluster avec réplication synchrone SQL AlwaysOn via IP. Ce schéma est l'une des options de haute qualité pour résoudre le problème de la résistance aux catastrophes de la base de données 1C (voir Figure 1). La technologie de clustering de bases de données SQL AlwaysOn est basée sur le principe de synchronisation en ligne des tables SQL entre les serveurs principal et de sauvegarde sans intervention de l'utilisateur final. Grâce à SQL Listener, il est possible de passer à un serveur SQL de sauvegarde en cas de panne du serveur principal, ce qui permet d'appeler ce système un cluster SQL à part entière à l'épreuve des catastrophes, grâce à l'utilisation de deux serveurs SQL indépendants. . La technologie SQL Always On est uniquement disponible dans l'édition Microsoft SQL Enterprise.

Figure 1 - schéma d'un cluster de serveurs 1C + SQL AlwaysOn
Le deuxième schéma est identique au premier, seul le chiffrement des bases de données SQL sur les serveurs principal et de sauvegarde est ajouté. Nous avons déjà mentionné que le travail sur des projets informatiques récents a montré que les entreprises ont commencé à accorder beaucoup plus d'attention à la question de la sécurité des données, pour diverses raisons - les exigences de la loi fédérale 152, les rachats de serveurs par des raiders, les fuites de données dans le cloud. , etc. Nous considérons donc cette version du schéma 1C comme tout à fait pertinente (voir Figure 2).

Figure 2 - schéma d'un cluster de serveurs 1C + SQL AlwaysOn avec cryptage
Un cluster de serveurs 1C « actifs-actifs » connectés à un seul serveur SGBD via IP. Contrairement aux besoins de tolérance aux pannes et de sécurité, certaines structures nécessitent avant tout des performances accrues, pour ainsi dire « toute la puissance de calcul ». Par conséquent, la priorité maximale est accordée à l'augmentation du nombre de clusters informatiques de serveurs 1C, dans lesquels la plate-forme 1C moderne permet de différencier différents types de calculs et de tâches d'arrière-plan (voir Figure 3). Bien entendu, la configuration des principales ressources du serveur SQL doit également être conforme aux normes, mais le serveur de base de données lui-même est présenté au singulier (apparemment, le calcul est fait pour une sauvegarde rapide des bases de données).

Figure 3 - schéma d'un cluster de serveurs 1C avec un serveur SGBD
Serveur 1C et SGBD sur un serveur matériel avec SharedMemory.Étant donné que nos tests pratiques visent à comparer les performances de différents systèmes, une sorte de norme est nécessaire pour comparer plusieurs options (voir Figure 4). En standard, à notre avis, vous devez prendre la disposition du serveur 1C et du SGBD sur un seul serveur matériel sans virtualisation avec interaction via SharedMemory.
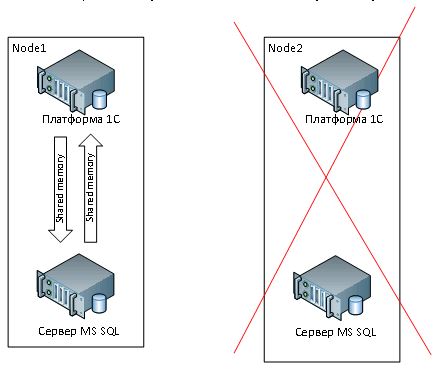
Figure 4 - schéma du serveur 1C et du SGBD sur un serveur matériel avec SharedMemory
Vous trouverez ci-dessous un tableau comparatif général qui montre les résultats globaux pour les critères clés d'évaluation de l'organisation de la structure du système 1C (voir tableau 1).
| Critères d'évaluation des architectures 1C | Cluster 1C + SQL toujours activé |
Cluster 1C + SQL AlwaysOn avec cryptage |
Cluster 1C avec un serveur SGBD |
Mémoire partagée classique 1C + SGBD |
| Facilité d'installation et d'entretien | Satisfait | Satisfait | Bien | Super |
| tolérance aux pannes | Super | Super | Satisfait | N'est pas applicable |
| Sécurité | Satisfait | Super | Satisfait | Satisfait |
| Budgétisation | Satisfait | Satisfait | Bien | Super |
Tableau 1 - comparaison des options pour la construction de systèmes 1C
Comme vous pouvez le constater, il reste un critère important dont la signification reste à déterminer : la productivité. Pour ce faire, nous réaliserons une série de tests pratiques sur un banc de test dédié.
Description de la méthodologie de test
La phase de test comprend deux outils clés pour la génération de charges synthétiques et la simulation du travail des utilisateurs dans 1C. Il s'agit du test Gilev (TPC-1C) et du « Test Center » de la boîte à outils 1C : Instrumentation.
Le test de Gilev. Le test appartient à la section des tests multiplateformes intégraux universels. Il peut être utilisé pour les versions fichier et client-serveur de 1C:Enterprise. Le test évalue la quantité de travail par unité de temps dans un thread et convient pour évaluer la vitesse des chargements monothread, y compris la vitesse de rendu de l'interface, l'impact des coûts des ressources sur la maintenance d'un environnement virtuel, la republication de documents, la fermeture du mois, calcul de la paie, etc. L'universalité vous permet d'effectuer une évaluation généralisée des performances sans être lié à une configuration de plate-forme typique spécifique. Le résultat du test est une évaluation récapitulative du système 1C mesuré, exprimé en unités conventionnelles.
"Centre de Test" spécialisé du 1C : Boîte à outils Instrumentation. Test Center est un outil d'automatisation des tests de charge multi-utilisateurs des systèmes d'information sur la plateforme 1C:Enterprise 8. Avec son aide, vous pouvez simuler le fonctionnement d'une entreprise sans la participation d'utilisateurs réels, ce qui vous permet d'évaluer l'applicabilité, performances et évolutivité d’un système d’information en conditions réelles. À l'aide des outils 1C : KIP, sur la base des processus et des cas de test, la matrice « Liste des objets de la configuration de la base de données ERP 2.2 » est générée pour le scénario de test de performances. Dans l'agencement de la base de données 1C : ERP 2.2, les données sont générées par traitement selon les Informations Réglementaires de Référence (RNI) :
- Plusieurs milliers d'articles de nomenclature ;
- Plusieurs organismes;
- Plusieurs milliers de contreparties.
Le test est réalisé au sein de plusieurs groupes d'utilisateurs. Le groupe est composé de 4 utilisateurs, chacun ayant son propre rôle et une liste d'opérations séquentielles. Grâce au mécanisme flexible de définition des paramètres de test, vous pouvez exécuter un test sur un nombre différent d'utilisateurs, ce qui vous permettra d'évaluer le comportement du système sous différentes charges et d'identifier les paramètres pouvant entraîner une diminution des indicateurs de performance. 3 tests sont réalisés en 3 itérations dans lesquelles le développeur 1C exécute un test émulant le travail de l'utilisateur et mesure le temps d'exécution de chaque opération. Les trois itérations sont mesurées pour chacun des schémas de structure 1C. Le résultat du test est d'obtenir le temps moyen d'exécution des opérations pour chaque document matriciel.
Les indicateurs du « Test Center » et du test Gilev seront reflétés dans le tableau récapitulatif 2.
Banc d'essai
Serveur d'accès aux terminaux– machine virtuelle, utilisée pour gérer les outils de tests :
- processeur virtuel - 16 cœurs 2,6 GHz
- RAM - 32 Go
- I\o : Intel Sata SSD Raid1
- RAM - 96 Go
- I\o : Intel Sata SSD Raid1
Serveur 1C et SGBD - serveur physique
- CPU - Processeur Intel Xeon E5-2670 8C 2,6 GHz – 2 pièces.
- RAM - 96 Go
- I\o : Intel Sata SSD Raid1
- Rôles : 1C Server 8.3.8.2137, MS SQL Server 2014 SP 2
conclusions
Nous pouvons conclure que, sur la base du temps de fonctionnement moyen, le plus optimal est le schéma n°3 « Cluster de serveurs « actifs-actifs » 1C connectés à un seul serveur SGBD via le protocole IP » (voir tableau 2). Pour garantir la tolérance aux pannes d'une telle architecture, nous vous recommandons de créer un cluster de basculement MSSQL classique avec la base de données située sur un système de stockage distinct.
Il est important de noter que l'équilibre le plus optimal de facteurs pour minimiser les temps d'arrêt, la tolérance aux pannes et la sécurité des données se trouve dans le schéma n°1 « Cluster de serveurs 1C connectés à un cluster avec réplication synchrone SQL AlwaysOn via IP », tandis que la baisse des performances par rapport à l'option la plus productive est d'environ 10 %.
Comme le montrent les résultats des tests, la réplication synchrone de la base de données AlwaysOn SQL a un impact plutôt négatif sur les performances. Cela s'explique par le fait que le système SQL attend la fin de la réplication de chaque transaction sur le serveur de sauvegarde, ne permettant pas de travailler avec la base de données à ce moment-là. Cela peut être évité en configurant une réplication asynchrone entre les serveurs MSSQL, mais avec de tels paramètres, nous n'obtiendrons pas de basculement automatique des applications vers le nœud de sauvegarde en cas de panne. Le changement devra être effectué manuellement.
Basés sur le cloud EFSOL, nous proposons à nos clients Grappe de serveurs 1C a louer. Cela vous permet d'économiser considérablement de l'argent sur la création de votre propre architecture tolérante aux pannes pour travailler avec 1C.
|
Schéma d'architecture 1C |
Temps moyen pour terminer une opération, sec | ||