Calculs en SQL. Fonctions d'agrégation SQL - SUM, MIN, MAX, AVG, COUNT Utilisation de la fonction COUNT() avec un exemple
J'ai une demande du genre :
SELECT i.*, COUNT(*) AS devises, SUM(ig.quantity) AS total, SUM(g.price * ig.quantity) AS prix, c.briefly AS cname FROM facture AS i, bill_goods AS ig, good g LEFT JOIN devise c ON (c.id = g.currency) OÙ ig.invoice_id = i.id AND g.id = ig.good_id GROUP BY g.currency ORDER BY i.date DESC;
ceux. une liste de commandes est sélectionnée, dans laquelle les coûts totaux des marchandises dans différentes devises sont calculés (la devise est définie pour le produit, la colonne cname dans le résultat est le nom de la devise)
vous devez obtenir le nombre d'enregistrements avec le même i.id dans la colonne de résultat des devises, cependant, les expériences avec les paramètres COUNT() n'ont abouti à rien - il renvoie toujours 1
Question : Est-il possible d'obtenir la vraie valeur dans la colonne des devises ? Ceux. si les marchandises sont commandées avec des prix dans 3 devises différentes, devises=3 ?
Cependant, MySQL prend trop de libertés par rapport à SQL. Par exemple, que signifie i.* dans le contexte de cette sélection ? Toutes les colonnes du tableau des factures ? Puisqu'aucune fonction de groupe ne s'applique à eux, ce serait bien s'ils étaient répertoriés dans GROUP BY, sinon le principe de regroupement des lignes n'est pas tout à fait clair. Si vous devez recevoir toutes les marchandises pour toutes les commandes par devise, c'est une chose, si vous devez recevoir toutes les marchandises regroupées par devise pour chaque commande, c'est complètement différent.
En fonction de votre sélection, nous pouvons supposer la structure de données suivante :
Tableau des factures :
Table Facture_goods :
Tableau des marchandises :
Tableau des devises :
Quel sera le retour de votre sélection actuelle ? En théorie, il renverra N lignes pour chaque commande pour chaque devise dans laquelle cette commande contient des marchandises. Mais du fait que rien d'autre que g.currency n'est spécifié dans group by, ce n'est pas évident :), de plus, la colonne c.briefly contribue également à la formation implicite de groupes. Ce que nous avons comme résultat, pour chaque combinaison unique de i.*, g.currency et c.briefly, un groupe sera formé aux lignes duquel les fonctions SUM et COUNT seront appliquées. Le fait qu'en jouant avec le paramètre COUNT, vous ayez toujours obtenu 1 signifie qu'il n'y avait qu'un seul enregistrement dans le groupe résultant (c'est-à-dire que les groupes ne sont pas formés comme vous pourriez en avoir besoin, pouvez-vous décrire les exigences plus en détail ?). D'après votre question, ce que vous aimeriez savoir ne ressort pas clairement : combien de devises différentes ont été impliquées dans la commande ou combien de commandes ont été effectuées dans une devise donnée ? Dans le premier cas, plusieurs options sont possibles, tout dépend des capacités de MySQL ; dans le second, vous devez écrire l'expression select différemment.
Cependant, MySQL prend trop de libertés par rapport à SQL. Par exemple, que signifie i.* dans le contexte de cette sélection ? Toutes les colonnes du tableau des factures ?
Oui, exactement. Mais cela ne joue pas un grand rôle, car... Il n'y a aucune colonne utile parmi elles dans ce cas. Laissez-moi.* être je.id. Pour être précis.
Quel sera le retour de votre sélection actuelle ? En théorie, il renverra N lignes pour chaque commande pour chaque devise dans laquelle cette commande contient des marchandises. Mais du fait que group by ne précise rien d'autre que g.currency, ce n'est pas évident :),
Exactement.
Il renverra ce qui suit (dans cet exemple, dans i je sélectionne uniquement id , et pas toutes les colonnes) :
| identifiant | devises | total | prix | nom c |
|---|---|---|---|---|
| 33 | 1 | 1.00 | 198.00 | B.F. |
| 33 | 1 | 4.00 | 1548.04 | FROTTER |
De plus, la colonne c.briefly contribue également à la formation implicite de groupes.
Comment? Les tables sont jointes par c.id=g.currency et regroupées par g.currency .
Le fait qu'en jouant avec le paramètre COUNT, vous obteniez toujours 1 signifie qu'il n'y avait qu'un seul enregistrement dans le groupe résultant.
Non, le groupe a été construit à partir de 1er enregistrements. Autant que je sache, COUNT() renvoie 1 pour cette raison (après tout, les colonnes différentes dans le groupe (bien que, à l'exception de la colonne monétaire) soient créées par des fonctions d'agrégation).
(c'est-à-dire que les groupes ne sont pas formés comme vous le souhaiteriez, pouvez-vous décrire les exigences plus en détail ?).
Des groupes sont constitués selon les besoins, chaque groupe -- Ce coût total des marchandises dans chaque devise. Cependant, à part ça, je il faut calculer combien ou éléments dans ce groupe.
D'après votre question, ce que vous aimeriez savoir ne ressort pas clairement : combien de devises différentes ont été impliquées dans la commande ou combien de commandes ont été effectuées dans une devise donnée ?
Ouais, j'ai gagné un peu d'argent. Juste le premier.
dmig[dossier]
Par participation "implicite" à la formation d'un groupe, j'entends que si la colonne n'est pas spécifiée dans GROUP BY, et en même temps n'est PAS un argument pour la fonction de groupe, alors le résultat de la sélection sera identique à ce que ce serait si cette colonne était spécifiée dans GROUP BY. Votre sélection et la sélection ci-dessous produiront exactement le même résultat (ne faites pas attention aux jointures, je les ai simplement amenées dans un seul format d'enregistrement) :
Sélectionnez l'identifiant i.id, le nombre (*) de devises, la somme (ig.quantity) total, le prix SUM (g.price * ig.quantity), c.briefly cname FROM facture i joins bill_goods ig on (ig.invoice_id = i. id) rejoindre good g on (g.id = ig.good_id) LEFT OUTER JOIN devise c ON (c.id = g.currency) groupe par i.id, c.briefly
Il s'avère que dans chaque ligne de l'échantillon résultant, il y a une et une seule devise (si elle était différente, il y aurait alors deux lignes). De combien d’éléments parlons-nous dans ce cas ? À propos des articles commandés ? Alors votre sélection est tout à fait correcte, rien que pour cette devise, il n'y a qu'un seul élément dans cet ordre.
Regardons le schéma de données :
- Il y a plusieurs articles (lignes) dans une seule commande, n'est-ce pas ?
- Chaque article est un produit dans le répertoire des marchandises, n'est-ce pas ?
- Chaque produit a une devise spécifique (et une seule), cela découle de c.id = g.currency, non ?
Combien de devises y a-t-il dans la commande ? Il contient autant de points avec des devises DIFFÉRENTES.
L'ajout de g.price * ig.quantity n'a de sens que pour les points dans une seule devise ;) (bien que les kilomètres avec les heures puissent également être ajoutés :) Alors, qu'est-ce qui ne vous convient pas !? Vous indiquez que vous avez besoin du nombre de devises différentes impliquées dans la commande.
et dans ce cas, faire cela dans le cadre de la même sélection sans toutes sortes d'astuces (ce que MySQL ne fera probablement pas) ne fonctionnera pas ;(
Malheureusement, je ne suis pas un expert MySQL. Dans Oracle, vous pouvez le faire en une seule sélection, mais ces conseils vous aideront-ils ? À peine;)
# Il y a plusieurs articles (lignes) dans une seule commande, n'est-ce pas ?
# Chaque article est un produit dans le répertoire des marchandises, n'est-ce pas ?
# Chaque produit a une devise spécifique (et une seule), cela découle de c.id = g.currency, non ?
Donc.
Une commande : un enregistrement dans la table des factures, cela correspond à n(>0) enregistrements dans bill_goods, dont chacun correspond à 1 enregistrement dans la table des marchandises, l'enregistrement « devise » dans chacun d'eux, à son tour, correspond au 1er enregistrement dans la table des devises (LEFT JOIN - en cas d'édition du répertoire des devises avec des mains tordues - les tables comme MyISAM ne prennent pas en charge les clés étrangères).
Combien de devises y a-t-il dans la commande ? Il contient autant de points avec des devises DIFFÉRENTES.
Oui, exactement.
L'ajout de g.price * ig.quantity n'a de sens que pour les points dans une devise ;) (bien que des kilomètres avec des heures puissent également être ajoutés :)
C'est pourquoi le regroupement est effectué par identifiant de devise (g.currency).
Dans Oracle, vous pouvez le faire en une seule sélection, mais ces conseils vous aideront-ils ?
M.b.
J'ai parlé un peu avec Oracle et je connais pl/sql.
Option 1.
Sélectionnez a.*, comptez (*) sur (partition par a.id) les devises de (sélectionnez l'identifiant i.id, somme (ig.quantity) total, SUM (g.price * ig.quantity) prix, c.briefly cname DEpuis la facture, je rejoins bill_goods ig sur (ig.invoice_id = i.id) rejoins good g sur (g.id = ig.good_id) LEFT OUTER JOIN devise c ON (c.id = g.currency) groupe par i.id, c.brièvement) a
Cela utilise ce qu'on appelle fonction analytique. Avec 99 % de probabilité, cela ne fonctionne PAS dans MySQL.
Option 2.
Une fonction est créée, countCurrencies par exemple, qui, en fonction de l'identifiant de la commande, renvoie le nombre de devises qui y ont participé puis :
Sélectionnez l'identifiant i.id, les devises countCurrencies(i.id), le total sum(ig.quantity), le prix SUM(g.price * ig.quantity), c.briefly cname FROM facture, je rejoins bill_goods ig sur (ig.invoice_id = i.id) rejoindre good g on (g.id = ig.good_id) LEFT OUTER JOIN devise c ON (c.id = g.currency) groupe par i.id, c.briefly, countCurrencies(i.id)
Cela peut fonctionner... mais il sera appelé pour chaque devise de chaque commande. Je ne sais pas si MySQL vous permet de faire GROUP BY par fonction...
Option n°3
Sélectionnez l'identifiant i.id, les devises agr.cnt, le total somme (ig.quantity), le prix SUM (g.price * ig.quantity), c.briefly cname FROM facture je rejoins bill_goods ig sur (ig.invoice_id = i.id ) rejoignez bien continuez (g.id = ig.good_id) LEFT OUTER JOIN devise c ON (c.id = g.currency) jointure externe gauche (sélectionnez ii.id, compte (gg.currency distinct) cnt de la facture ii, invoce_goods iig, good gg où ii.id = iig.invoice_id et gg.id = iig.good_id groupe par ii.id) agr sur (i.id = agr.id) groupe par i.id, c.briefly, agr. cnt
Probablement l’option la plus correcte… et probablement la plus efficace de toutes.
La plus rapide est l'option n°1. Le n°2 est le plus inefficace, car Plus il y a de devises dans la commande, plus elles sont comptées souvent.
Le n ° 3 n'est pas non plus, en principe, le meilleur en termes de vitesse, mais au moins vous pouvez compter sur la mise en cache dans le SGBD.
Le résultat des trois sélections sera le suivant :
| identifiant | devises | total | prix | nom c | ||||
|---|---|---|---|---|---|---|---|---|
| 33 | 2 | 1.00 | 198.00 | B.F. | ||||
| 33 | 2 | 4.00 | 1548.04 | FROTTER | ||||
pour le même identifiant, le numéro dans la colonne des devises sera toujours le même, est-ce ce dont vous avez besoin ?
SQL - Leçon 8. Regroupement d'enregistrements et fonction COUNT()
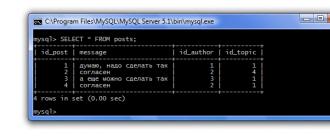
Rappelons-nous quels messages et dans quels sujets nous avons. Pour ce faire, vous pouvez utiliser la requête habituelle :
Et si nous avions juste besoin de savoir combien de messages il y a sur le forum. Pour ce faire, vous pouvez utiliser la fonction intégrée COMPTER(). Cette fonction compte le nombre de lignes. De plus, si * est utilisé comme argument de cette fonction, alors toutes les lignes du tableau sont comptées. Et si un nom de colonne est spécifié comme argument, seules les lignes qui ont une valeur dans la colonne spécifiée sont comptées.
Dans notre exemple, les deux arguments donneront le même résultat, car toutes les colonnes du tableau ne sont PAS NULLes. Écrivons une requête en utilisant la colonne id_topic comme argument :
SELECT COUNT(id_topic) FROM messages ;

Il y a donc 4 messages dans nos sujets. Mais que se passe-t-il si nous voulons savoir combien de messages il y a dans chaque sujet. Pour ce faire, nous devrons regrouper nos messages par thème et calculer le nombre de messages pour chaque groupe. Pour regrouper en SQL, utilisez l'opérateur PAR GROUPE. Notre requête ressemblera désormais à ceci :
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic ;
Opérateur PAR GROUPE indique au SGBD de regrouper les données par colonne id_topic (c'est-à-dire que chaque sujet est un groupe distinct) et de compter le nombre de lignes pour chaque groupe :

Eh bien, dans le sujet avec id=1, nous avons 3 messages, et avec id=4 - un. À propos, si des valeurs manquantes étaient possibles dans le champ id_topic, ces lignes seraient alors combinées dans un groupe distinct avec la valeur NULL.
Supposons que nous ne nous intéressons qu'aux groupes qui contiennent plus de deux messages. Dans une requête normale, nous spécifierions la condition à l'aide de l'opérateur OÙ, mais cet opérateur ne peut fonctionner qu'avec des chaînes, et pour les groupes, les mêmes fonctions sont remplies par l'opérateur AYANT:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic HAVING COUNT(id_topic) > 2 ;
En conséquence nous avons :

Dans la leçon 4, nous avons examiné quelles conditions peuvent être définies par l'opérateur OÙ, les mêmes conditions peuvent être précisées par l'opérateur AYANT, tu dois juste te rappeler que OÙ filtre les chaînes et AYANT- des groupes.
Aujourd’hui, nous avons appris à créer des groupes et à compter le nombre de lignes dans un tableau et dans des groupes. En général, en collaboration avec l'opérateur PAR GROUPE Vous pouvez utiliser d'autres fonctions intégrées, mais nous les étudierons plus tard.
Dans ce tutoriel, vous apprendrez à utiliser Fonction COMPTE dans SQL Server (Transact-SQL) avec syntaxe et exemples.
Description
Dans SQL Server (Transact-SQL) Fonction COMPTE renvoie le nombre de lignes d'un champ ou d'une expression dans le jeu de résultats.
Syntaxe
La syntaxe de la fonction COUNT dans SQL Server (Transact-SQL) est la suivante :
OU la syntaxe de la fonction COUNT lors du regroupement des résultats d'une ou plusieurs colonnes est :
Paramètres ou arguments
expression1 , expression2 , … expression_n
Expressions qui ne sont pas incluses dans une fonction COUNT et doivent être incluses dans une clause GROUP BY à la fin de l'instruction SQL.
gregate_expression est la colonne ou l'expression dont les valeurs non NULL seront comptées.
tables - tables à partir desquelles vous souhaitez obtenir des enregistrements. Il doit y avoir au moins une table répertoriée dans la clause FROM.
Conditions OÙ - facultatives. Ce sont les conditions qui doivent être remplies pour les enregistrements sélectionnés.
Inclure des valeurs non NULL
Tout le monde ne comprend pas cela, mais la fonction COUNT ne comptera que les enregistrements pour lesquels la valeur de l'expression dans COUNT (aggregate_expression) n'est pas NULL. Lorsqu'une expression contient une valeur NULL, elle n'est pas incluse dans le compteur COUNT.
Regardons un exemple de la fonction COUNT qui montre comment les valeurs NULL sont évaluées par la fonction COUNT.
Par exemple, si vous disposez du tableau suivant appelé marchés :
Cet exemple COUNT renverra 3 car toutes les valeurs market_id dans l'ensemble de résultats de la requête ne sont PAS NULL.
Toutefois, si vous avez exécuté l'instruction SELECT suivante, qui utilise la fonction COUNT :
Transact-SQL
SELECT COUNT(filials) FROM marchés ; --Résultat : 1
Cet exemple COUNT ne renverra que 1, car une seule valeur filiale dans le jeu de résultats de la requête n'est PAS NULL. Ce sera la première ligne qui dira filials = "oui". Il s'agit de la seule ligne incluse dans le calcul de la fonction COUNT.
Application
La fonction COUNT peut être utilisée dans les versions suivantes de SQL Server (Transact-SQL) :
SQL Server vNext, SQL Server 2016, SQL Server 2015, SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Exemple avec un champ
Examinons quelques exemples de fonctions COUNT de SQL Server pour comprendre comment utiliser la fonction COUNT dans SQL Server (Transact-SQL).
Par exemple, vous pouvez savoir combien de contacts possède un utilisateur avec last_name = "Rasputin".
Dans cet exemple de fonction COUNT, nous avons spécifié l'alias « Nombre de contacts » à l'expression COUNT (*). Par conséquent, le jeu de résultats affichera « Nombre de contacts » comme nom de champ.
Exemple utilisant DISTINCT
Vous pouvez utiliser l'opérateur DISTINCT dans la fonction COUNT. Par exemple, l'instruction SQL ci-dessous renvoie le nombre de services uniques dans lesquels au moins un employé a prénom = « Samvel ».
Comment puis-je connaître le nombre de modèles de PC produits par un fournisseur particulier ? Comment déterminer le prix moyen d’ordinateurs ayant les mêmes caractéristiques techniques ? Il est possible de répondre à ces questions et à bien d’autres liées à certaines informations statistiques en utilisant fonctions finales (agrégatives). La norme fournit les fonctions d'agrégation suivantes :
Toutes ces fonctions renvoient une valeur unique. Parallèlement, les fonctions COMPTE, MINIMUM Et MAXIMUM applicable à tout type de données, tandis que SOMME Et MOYENNE sont utilisés uniquement pour les champs numériques. Différence entre la fonction COMPTER(*) Et COMPTER(<имя поля>) est que le second ne prend pas en compte les valeurs NULL lors du calcul.
Exemple. Trouvez le prix minimum et maximum pour les ordinateurs personnels :
Exemple. Recherchez le nombre d'ordinateurs disponibles produits par le fabricant A :
Exemple. Si l'on s'intéresse au nombre de modèles différents produits par le fabricant A, alors la requête peut être formulée comme suit (en utilisant le fait que dans la table Produit chaque modèle est enregistré une fois) :
Exemple. Recherchez le nombre de modèles différents disponibles produits par le fabricant A. La requête est similaire à la précédente, dans laquelle il fallait déterminer le nombre total de modèles produits par le fabricant A. Ici, vous devez également trouver le nombre de modèles différents dans la table PC (c'est-à-dire celles disponibles à la vente).
Pour garantir que seules des valeurs uniques sont utilisées lors de l'obtention d'indicateurs statistiques, lorsque argument des fonctions d'agrégation peut être utilisé Paramètre DISTINCT. Un autre paramètre TOUS est la valeur par défaut et suppose que toutes les valeurs renvoyées dans la colonne sont comptées. Opérateur,
Si nous avons besoin d’obtenir le nombre de modèles de PC produits tout le monde fabricant, vous devrez utiliser Clause GROUPE PAR, suivant syntaxiquement OÙ clauses.
Clause GROUPE PAR
Clause GROUPE PAR utilisé pour définir des groupes de chaînes de sortie pouvant être appliquées à fonctions d'agrégation (COUNT, MIN, MAX, AVG et SUM). Si cette clause est manquante et que des fonctions d'agrégation sont utilisées, alors toutes les colonnes dont les noms sont mentionnés dans SÉLECTIONNER, devrait être inclus dans fonctions d'agrégation, et ces fonctions seront appliquées à l'ensemble des lignes qui satisfont au prédicat de requête. Sinon, toutes les colonnes de la liste SELECT non inclus dans les fonctions d'agrégation, il faut préciser dans la clause GROUP BY. En conséquence, toutes les lignes de requête de sortie sont divisées en groupes caractérisés par les mêmes combinaisons de valeurs dans ces colonnes. Après cela, des fonctions d'agrégation seront appliquées à chaque groupe. Veuillez noter que pour GROUP BY, toutes les valeurs NULL sont traitées comme égales, c'est-à-dire lors du regroupement par un champ contenant des valeurs NULL, toutes ces lignes tomberont dans un seul groupe.Si s'il y a une clause GROUP BY, dans la clause SELECT pas de fonctions d'agrégation, la requête renverra simplement une ligne de chaque groupe. Cette fonctionnalité, ainsi que le mot-clé DISTINCT, peuvent être utilisés pour éliminer les lignes en double dans un jeu de résultats.
Regardons un exemple simple :
| SELECT modèle, COUNT (modèle) AS Qty_model, AVG (prix) AS Avg_price À PARTIR DU PC Modèle GROUPE PAR ; |
Dans cette demande, pour chaque modèle de PC, leur nombre et leur coût moyen sont déterminés. Toutes les lignes avec la même valeur de modèle forment un groupe et la sortie de SELECT calcule le nombre de valeurs et les valeurs de prix moyennes pour chaque groupe. Le résultat de la requête sera le tableau suivant :
| modèle | Qté_modèle | Prix_moy. |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Si le SELECT avait une colonne de date, il serait alors possible de calculer ces indicateurs pour chaque date spécifique. Pour ce faire, vous devez ajouter la date en tant que colonne de regroupement, puis les fonctions d'agrégation seront calculées pour chaque combinaison de valeurs (modèle-date).
Il existe plusieurs spécifiques règles pour exécuter des fonctions d'agrégation:
- Si à la suite de la demande aucune ligne reçue(ou plus d'une ligne pour un groupe donné), alors il n'y a aucune donnée source pour calculer l'une des fonctions d'agrégation. Dans ce cas, le résultat des fonctions COUNT sera nul et le résultat de toutes les autres fonctions sera NULL.
- Argument fonction d'agrégation ne peut pas lui-même contenir des fonctions d'agrégation(fonction à partir de la fonction). Ceux. dans une requête, il est impossible, par exemple, d'obtenir le maximum de valeurs moyennes.
- Le résultat de l'exécution de la fonction COUNT est entier(ENTIER). D'autres fonctions d'agrégation héritent des types de données des valeurs qu'elles traitent.
- Si la fonction SOMME produit un résultat supérieur à la valeur maximale du type de données utilisé, erreur.
Ainsi, si la demande ne contient pas Clause GROUPE PAR, Que fonctions d'agrégation inclus dans Clause SELECT, sont exécutés sur toutes les lignes de requête résultantes. Si la demande contient Clause GROUPE PAR, chaque ensemble de lignes qui a les mêmes valeurs d'une colonne ou d'un groupe de colonnes spécifié dans Clause GROUPE PAR, constitue un groupe, et fonctions d'agrégation sont effectués pour chaque groupe séparément.
AVOIR une offre
Si Clause OÙ définit un prédicat pour filtrer les lignes, puis AVOIR une offre s'applique après le regroupement pour définir un prédicat similaire qui filtre les groupes par valeurs fonctions d'agrégation. Cette clause est nécessaire pour valider les valeurs obtenues en utilisant fonction d'agrégation pas à partir de lignes individuelles de la source d'enregistrement définie dans Clause DE, et de groupes de telles lignes. Un tel contrôle ne peut donc pas être contenu dans Clause OÙ.
Pour déterminer le nombre d'enregistrements dans une table MySQL, vous devez utiliser la fonction spéciale COUNT().
La fonction COUNT() renvoie le nombre d'enregistrements dans une table qui correspondent à un critère donné.
La fonction COUNT(expr) compte toujours uniquement les lignes pour lesquelles le résultat de expr est NOT NULL .
L'exception à cette règle concerne l'utilisation de la fonction COUNT() avec un astérisque comme argument - COUNT(*) . Dans ce cas, toutes les lignes sont comptées, qu'elles soient NULL ou NOT NULL.
Par exemple, la fonction COUNT(*) renvoie le nombre total d'enregistrements dans la table :
SELECT COUNT(*) FROM nom_table
Comment compter le nombre d'enregistrements et les afficher à l'écran
Exemple de code PHP+MySQL pour compter et afficher le nombre total de lignes :
$res = mysql_query("SELECT COUNT(*) FROM table_name") $row = mysql_fetch_row($res); $total = $ligne ; // total des enregistrements echo $total; ?>
Cet exemple illustre l'utilisation la plus simple de la fonction COUNT(). Mais vous pouvez également effectuer d'autres tâches en utilisant cette fonction.
En spécifiant une colonne de table spécifique comme paramètre, la fonction COUNT(column_name) renvoie le nombre d'enregistrements dans cette colonne qui ne contiennent pas de valeur NULL. Les enregistrements avec des valeurs NULL sont ignorés.
SELECT COUNT (nom_colonne) FROM nom_table
La fonction mysql_num_rows() ne peut pas être utilisée car pour connaître le nombre total d'enregistrements, vous devez exécuter une requête SELECT * FROM db, c'est-à-dire obtenir tous les enregistrements, ce qui n'est pas souhaitable, il est donc préférable de utilisez la fonction de comptage.
$result = mysql_query("SELECT COUNT (*) as rec FROM db");
Utilisation de la fonction COUNT() comme exemple
Voici un autre exemple d'utilisation de la fonction COUNT(). Disons qu'il existe une table ice_cream avec un catalogue de glaces, qui contient des identifiants de catégorie et des noms de glaces.