Izračuni u sql. SQL agregatne funkcije - SUM, MIN, MAX, AVG, COUNT Upotreba funkcije COUNT() s primjerom
imam zahtjev kao:
SELECT i.*, COUNT(*) AS valute, SUM(ig.količina) KAO ukupno, SUM(g.price * ig.quantity) AS cijena, c.kratko AS cname FROM fakture AS i, fakture_goods AS ig, good g LEFT JOIN valuta c UKLJUČENO (c.id = g.currency) GDJE ig.invoice_id = i.id I g.id = ig.good_id GROUP BY g.currency ORDER BY i.date DESC;
one. bira se lista narudžbi u kojoj se obračunavaju ukupni troškovi robe u različitim valutama (valuta se postavlja za proizvod, kolona cname u rezultatu je naziv valute)
morate dobiti broj zapisa sa istim i.id-om u stupcu rezultata valute, međutim eksperimenti sa parametrima COUNT() nisu doveli do ničega - uvijek vraća 1
Pitanje: Da li je moguće dobiti pravu vrijednost u stupcu valuta? One. ako se roba naručuje sa cijenama u 3 različite valute, valute=3 ?
Međutim, MySQL uzima previše slobode u odnosu na SQL. Na primjer, šta znači i.* u kontekstu ovog odabira? Sve kolone tabele faktura? Budući da se na njih ne odnosi nijedna grupna funkcija, bilo bi dobro da su navedeni u GROUP BY, inače princip grupisanja redova nije sasvim jasan. Ako trebate primiti svu robu za sve narudžbe po valuti, ovo je jedno, ako trebate primiti svu robu grupiranu po valuti za svaku narudžbu, ovo je potpuno drugačije.
Na osnovu vašeg odabira, možemo pretpostaviti sljedeću strukturu podataka:
Tabela faktura:
Tabela faktura_roba:
Sto za robu:
Tabela valuta:
Šta će vaš trenutni odabrani vratiti? U teoriji, vratit će N redova za svaku narudžbu za svaku valutu u kojoj ovaj nalog sadrži robu. Ali zbog činjenice da ništa osim g.currency nije navedeno u grupi po, to nije očigledno :), štaviše, kolona c.briefly takođe doprinosi implicitnom formiranju grupa. Ono što imamo kao rezultat, za svaku jedinstvenu kombinaciju i.*, g.valuta i c.kratko, formiraće se grupa na čije linije će biti primenjene funkcije SUM i COUNT. Činjenica da ste kao rezultat igranja sa COUNT parametrom uvijek dobili 1 znači da je postojao samo jedan zapis u nastaloj grupi (tj. grupe nisu formirane kako vam je potrebno, možete li detaljnije opisati zahtjeve?). Iz vašeg pitanja nije jasno šta biste željeli znati - koliko je različitih valuta bilo uključeno u nalog ili koliko je naloga bilo u datoj valuti? U prvom slučaju moguće je nekoliko opcija, sve ovisi o mogućnostima MySQL-a, u drugom slučaju morate drugačije napisati izraz za odabir.
Međutim, MySQL uzima previše slobode u odnosu na SQL. Na primjer, šta znači i.* u kontekstu ovog odabira? Sve kolone tabele faktura?
Da upravo. Ali to ne igra veliku ulogu, jer... Među njima u ovom slučaju nema korisnih kolona. Neka je i.* i.id. Da budem konkretni.
Šta će vaš trenutni odabir vratiti? U teoriji, vratit će N redova za svaku narudžbu za svaku valutu u kojoj ovaj nalog sadrži robu. Ali zbog činjenice da grupa by ne navodi ništa osim g.currency, to nije očigledno :),
Upravo.
Vratit će sljedeće (u ovom primjeru, iz i biram samo id, a ne sve kolone):
| id | valute | ukupno | Cijena | cname |
|---|---|---|---|---|
| 33 | 1 | 1.00 | 198.00 | B.F. |
| 33 | 1 | 4.00 | 1548.04 | RUB |
Štaviše, rubrika c.brifly također doprinosi implicitnom formiranju grupa.
Kako? Tabele su spojene pomoću c.id=g.currency i grupisane po g.currency.
Činjenica da ste kao rezultat igranja sa COUNT parametrom uvijek dobili 1 znači da je postojao samo jedan zapis u rezultirajućoj grupi
Ne, grupa je napravljena od 1st evidencije. Koliko ja razumijem, COUNT() vraća 1 iz tog razloga (na kraju krajeva, kolone koje se razlikuju u grupi (iako, osim stupca valute) kreiraju agregatne funkcije).
(tj. grupe nisu formirane kako vam je potrebno, možete li detaljnije opisati zahtjeve?).
Grupe se formiraju po potrebi, svaka grupa -- Ovo ukupni trošak robe u svakoj valuti. Međutim, pored toga, I treba izračunati koliko isto elementi u ovo grupa.
Iz vašeg pitanja nije jasno šta biste željeli znati - koliko je različitih valuta bilo uključeno u nalog ili koliko je naloga bilo u datoj valuti?
Da, zaradio sam malo novca. Samo prvi.
dmig[dosije]
Pod "implicitnim" učešćem u formiranju grupe, mislim da ako kolona nije navedena u GROUP BY, a u isto vrijeme NIJE argument funkciji grupe, tada će rezultat odabira biti identičan šta bi bilo da je taj stupac bio specificiran u GROUP BY. Vaš odabir i odabir ispod dat će potpuno isti rezultat (ne obraćajte pažnju na spojeve, upravo sam ih doveo u jedan format snimanja):
Odaberite i.id id, count(*) valute, zbir(ig.količina) ukupni, SUM(g.price * ig.količina) cijenu, c.ukratko cname FROM fakture i pridružim invoice_goods ig on (ig.invoice_id = i. id) pridruži se dobrom g na (g.id = ig.good_id) LEFT OUTER JOIN valuta c ON (c.id = g.currency) grupi po i.id, c.kratko
Ispada da u svakom redu rezultirajućeg uzorka postoji jedna i samo jedna valuta (da je drugačija, onda bi bila dva reda). O kom broju elemenata govorimo u ovom slučaju? O artiklima narudžbe? Tada je vaš odabir potpuno ispravan, samo za ovu valutu postoji samo jedna stavka u ovom redoslijedu.
Pogledajmo šemu podataka:
- Postoji mnogo stavki (redova) u jednoj narudžbi, zar ne?
- Svaka stavka je proizvod u katalogu robe, zar ne?
- Svaki proizvod ima specifičnu (i samo jednu) valutu, to proizilazi iz c.id = g.currency, zar ne?
Koliko je valuta u narudžbi? U njemu ima isto toliko bodova sa RAZLIČITIM valutama.
Dodavanje g.cijene * ig.količine ima smisla samo za bodove u jednoj valuti;) (iako se mogu dodati i kilometri sa satima :) Pa šta vam ne odgovara!? Navodite da vam je potrebno koliko različitih valuta je uključeno u narudžbu
i u ovom slučaju, raditi ovo u okviru istog odabira bez svih vrsta trikova (koje MySQL najvjerovatnije neće učiniti) neće raditi;(
Nažalost, nisam stručnjak za MySQL. U Oracleu to možete učiniti s jednim odabirom, ali hoće li vam ovaj savjet pomoći? Teško ;)
# Postoji mnogo stavki (redova) u jednoj narudžbi, zar ne?
# Svaka stavka je proizvod u katalogu robe, zar ne?
# Svaki proizvod ima specifičnu (i samo jednu) valutu, ovo proizilazi iz c.id = g.currency, zar ne?
Dakle.
Jedna narudžba: jedan zapis u tabeli faktura, odgovara n(>0) zapisa u fakturi_goods, od kojih svaki odgovara 1 zapisu u tabeli robe, zapis „valute“ u svakom od njih, zauzvrat, odgovara 1. zapis u tabeli valuta ( LEFT JOIN - u slučaju uređivanja valutnog imenika sa krivim rukama - tabele kao što je MyISAM ne podržavaju strane ključeve).
Koliko je valuta u narudžbi? U njemu ima isto toliko bodova sa RAZLIČITIM valutama.
Da upravo.
Dodavanje g.price * ig.quantity ima smisla samo za bodove u jednoj valuti;) (iako se mogu dodati i kilometri sa satima :)
Zbog toga se grupisanje vrši po ID-u valute (g.currency).
U Oracleu to možete učiniti s jednim odabirom, ali hoće li vam ovaj savjet pomoći?
M.b.
Malo sam pričao sa Oracleom i upoznat sam sa pl/sql.
Opcija #1.
Odaberite a.*, računajte(*) preko (podijelite po a.id) valute iz (odaberite i.id id, sum(ig.quantity) total, SUM(g.price * ig.quantity) cijena, c.ukratko cname IZ fakture i pridružujem se invoice_goods ig on (ig.invoice_id = i.id) pridruži se dobrom g na (g.id = ig.good_id) LIJEVO VANJSKO PRIDRUŽENJE valuti c ON (c.id = g.currency) grupi po i.id, c.ukratko)a
Ovo koristi tzv analitička funkcija. Sa vjerovatnoćom od 99% NE radi u MySQL-u.
Opcija #2.
Kreira se funkcija, na primjer countCurrencies, koja na osnovu ID-a narudžbe vraća broj valuta koje su učestvovale u njoj i zatim:
Odaberite i.id id, countCurrencies(i.id) valute, zbir(ig.količina) ukupan, SUM(g.price * ig.quantity) cijenu, c.ukratko cname FROM fakture i pridružim invoice_goods ig on (ig.invoice_id = i.id) pridruži dobro g na (g.id = ig.good_id) LEFT OUTER JOIN valuta c ON (c.id = g.currency) grupi po i.id, c.ukratko, countCurrenci(i.id)
Možda radi... ali će biti pozvan za svaku valutu svake narudžbe. Ne znam da li vam MySQL dozvoljava da radite GROUP BY po funkciji...
Opcija #3
Odaberite i.id id, agr.cnt valute, sumu(ig.količina) ukupno, SUM(g.price * ig.quantity) cijenu, c.ukratko cname FROM fakture i pridružite invoice_goods ig on (ig.invoice_id = i.id). ) pridruži dobro ide dalje (g.id = ig.good_id) LEFT OUTER JOIN valuta c ON (c.id = g.currency) lijevo vanjsko spajanje (odaberite ii.id, count(distinct gg.currency) cnt iz fakture ii, invoce_goods iig, good gg gdje je ii.id = iig.invoice_id i gg.id = iig.good_id grupa po ii.id) agr on (i.id = agr.id) grupa po i.id, c.ukratko, agr. cnt
Vjerovatno najispravnija... i vrlo vjerojatno najradnija opcija od svih.
Najbrža je opcija br. 1. Broj 2 je najneefikasniji, jer Što je više valuta u nalogu, to se češće broje.
Br. 3 također, u principu, nije najbolji u smislu brzine, ali se barem možete osloniti na keširanje unutar DBMS-a.
Rezultat sva tri odabira će biti sljedeći:
| id | valute | ukupno | Cijena | cname | ||||
|---|---|---|---|---|---|---|---|---|
| 33 | 2 | 1.00 | 198.00 | B.F. | ||||
| 33 | 2 | 4.00 | 1548.04 | RUB | ||||
za isti ID broj u koloni valuta će uvijek biti isti, da li vam je ovo potrebno?
SQL - Lekcija 8. Grupiranje zapisa i funkcija COUNT().
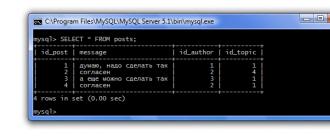
Prisjetimo se koje poruke i u kojim temama imamo. Da biste to učinili, možete koristiti uobičajeni upit:
Šta ako samo trebamo saznati koliko poruka ima na forumu. Da biste to učinili, možete koristiti ugrađenu funkciju COUNT(). Ova funkcija broji broj redova. Štaviše, ako se * koristi kao argument za ovu funkciju, tada se broje svi redovi tabele. A ako je ime kolone navedeno kao argument, tada se broje samo oni redovi koji imaju vrijednost u navedenoj koloni.
U našem primjeru, oba argumenta će dati isti rezultat, jer sve kolone tabele NISU NULL. Napišimo upit koristeći kolonu id_topic kao argument:
SELECT COUNT(id_topic) FROM postova;

Dakle, postoje 4 poruke u našim temama. Ali šta ako želimo da znamo koliko poruka ima u svakoj temi. Da bismo to učinili, morat ćemo grupirati naše poruke po temama i izračunati broj poruka za svaku grupu. Za grupisanje u SQL-u koristite operator GROUP BY. Naš zahtjev će sada izgledati ovako:
SELECT id_topic, COUNT(id_topic) FROM postova GROUP BY id_topic;
Operater GROUP BY govori DBMS-u da grupira podatke prema stupcu id_topic (tj. svaka tema je zasebna grupa) i izbroji broj redova za svaku grupu:

Pa u temi sa id=1 imamo 3 poruke, a sa id=4 - jednu. Usput, ako bi nedostajuće vrijednosti bile moguće u polju id_topic, tada bi se takvi redovi kombinirali u posebnu grupu s vrijednošću NULL.
Pretpostavimo da nas zanimaju samo one grupe koje imaju više od dvije poruke. U normalnom upitu, specificirali bismo uvjet koristeći operator GDJE, ali ovaj operator može raditi samo sa stringovima, a za grupe iste funkcije obavlja operator HAVING:
SELECT id_topic, COUNT(id_topic) IZ postova GRUPA PO id_topic IMAJUĆI COUNT(id_topic) > 2;
Kao rezultat imamo:

U lekciji 4 pogledali smo koje uslove može postaviti operater GDJE, iste uslove može odrediti operator HAVING, samo treba da zapamtite to GDJE filtrira nizove i HAVING- grupe.
Dakle, danas smo naučili kako da kreiramo grupe i kako da prebrojimo broj redova u tabeli iu grupama. Općenito, zajedno sa operaterom GROUP BY Možete koristiti i druge ugrađene funkcije, ali ćemo ih kasnije proučiti.
U ovom vodiču ćete naučiti kako koristiti COUNT funkcija u SQL Serveru (Transact-SQL) sa sintaksom i primjerima.
Opis
U SQL Serveru (Transact-SQL) COUNT funkcija vraća broj redova polja ili izraza u skupu rezultata.
Sintaksa
Sintaksa za funkciju COUNT u SQL Serveru (Transact-SQL) je:
ILI sintaksa za funkciju COUNT kada grupišete rezultate jedne ili više kolona je:
Parametri ili argumenti
izraz1 , izraz2 , … izraz_n
Izrazi koji nisu zatvoreni u funkciji COUNT i moraju biti uključeni u klauzulu GROUP BY na kraju SQL izraza.
aggregate_expression je stupac ili izraz čije će se vrijednosti koje nisu NULL brojati.
tabele - tabele iz kojih želite da dobijete zapise. Mora postojati barem jedna tabela navedena u klauzuli FROM.
GDJE uslovi - opciono. Ovo su uslovi koji moraju biti ispunjeni za odabrane zapise.
Uključujući vrijednosti koje nisu NULL
Ne razumiju svi ovo, ali funkcija COUNT će brojati samo one zapise kod kojih vrijednost izraza u COUNT (aggregate_expression) nije NULL. Kada izraz sadrži NULL vrijednost, on nije uključen u brojač COUNT.
Pogledajmo primjer funkcije COUNT koja pokazuje kako se NULL vrijednosti procjenjuju pomoću funkcije COUNT.
Na primjer, ako imate sljedeću tabelu koja se zove tržišta:
Ovaj COUNT primjer će vratiti 3 jer sve vrijednosti market_id u skupu rezultata upita NISU NULL.
Međutim, ako ste pokrenuli sljedeću SELECT naredbu, koja koristi funkciju COUNT:
Transact-SQL
SELECT COUNT(filials) FROM markets; --Rezultat: 1
Ovaj COUNT primjer će vratiti samo 1, budući da samo jedna filijalna vrijednost u skupu rezultata upita NIJE NULL. Ovo će biti prvi red koji kaže filials = "da". Ovo je jedini red koji je uključen u izračun funkcije COUNT.
Aplikacija
Funkcija COUNT može se koristiti u sljedećim verzijama SQL Servera (Transact-SQL):
SQL Server vNext, SQL Server 2016, SQL Server 2015, SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Primjer sa jednim poljem
Pogledajmo neke primjere funkcije COUNT SQL Servera da bismo razumjeli kako koristiti funkciju COUNT u SQL Serveru (Transact-SQL).
Na primjer, možete saznati koliko kontakata ima korisnik sa prezime_name = "Rasputin".
U ovom primjeru funkcije COUNT, specificirali smo pseudonim “Broj kontakata” izrazu COUNT (*). Stoga će skup rezultata prikazati "Broj kontakata" kao ime polja.
Primjer koristeći DISTINCT
Možete koristiti DISTINCT operator u funkciji COUNT. Na primjer, SQL naredba u nastavku vraća broj jedinstvenih odjela u kojima barem jedan zaposlenik ima first_name = 'Samvel'.
Kako mogu saznati broj modela računara proizvedenih od strane određenog dobavljača? Kako odrediti prosječnu cijenu računara sa istim tehničkim karakteristikama? Na ova i mnoga druga pitanja u vezi sa nekim statističkim informacijama može se odgovoriti pomoću konačne (agregatne) funkcije. Standard pruža sljedeće agregatne funkcije:
Sve ove funkcije vraćaju jednu vrijednost. Istovremeno, funkcije COUNT, MIN I MAX primjenjivo na bilo koji tip podataka, dok SUMA I AVG se koriste samo za numerička polja. Razlika između funkcija COUNT(*) I COUNT(<имя поля>) je da drugi ne uzima u obzir NULL vrijednosti prilikom izračunavanja.
Primjer. Pronađite minimalnu i maksimalnu cijenu za personalne računare:
Primjer. Pronađite raspoloživi broj računara proizvođača A:
Primjer. Ako nas zanima broj različitih modela koje proizvodi proizvođač A, onda se upit može formulirati na sljedeći način (koristeći činjenicu da se u tablici proizvoda svaki model bilježi jednom):
Primjer. Pronađite broj dostupnih različitih modela proizvođača A. Upit je sličan prethodnom, u kojem se tražilo da se odredi ukupan broj modela proizvedenih od strane proizvođača A. Ovdje je potrebno pronaći i broj različitih modela u PC stol (tj. one dostupne za prodaju).
Kako bi se osiguralo da se pri dobijanju statističkih pokazatelja koriste samo jedinstvene vrijednosti, kada argument agregatnih funkcija može biti korišteno DISTINCT parametar. Drugi parametar SVE je zadana vrijednost i pretpostavlja da se sve vraćene vrijednosti u koloni broje. operater,
Ako trebamo dobiti broj proizvedenih modela PC-a svima proizvođača, morat ćete koristiti GROUP BY klauzula, sintaktički slijedi nakon WHERE klauzule.
GROUP BY klauzula
GROUP BY klauzula koristi se za definiranje grupa izlaznih nizova na koje se može primijeniti agregatne funkcije (COUNT, MIN, MAX, AVG i SUM). Ako ova klauzula nedostaje i koriste se agregatne funkcije, tada se koriste svi stupci s imenima navedenim u SELECT, treba uključiti u agregatne funkcije, a ove funkcije će se primijeniti na cijeli skup redova koji zadovoljavaju predikat upita. Inače, sve kolone SELECT liste nisu uključeni u agregatnim funkcijama moraju biti specificirane u klauzuli GROUP BY. Kao rezultat toga, svi redovi izlaznog upita podijeljeni su u grupe koje karakteriziraju iste kombinacije vrijednosti u ovim stupcima. Nakon toga, agregatne funkcije će se primijeniti na svaku grupu. Imajte na umu da se za GROUP BY sve NULL vrijednosti tretiraju kao jednake, tj. kada se grupiše po polju koje sadrži NULL vrijednosti, svi takvi redovi će pasti u jednu grupu.Ako ako postoji klauzula GROUP BY, u klauzuli SELECT nema agregatnih funkcija, onda će upit jednostavno vratiti jedan red iz svake grupe. Ova funkcija, zajedno sa ključnom riječi DISTINCT, može se koristiti za eliminaciju duplih redova u skupu rezultata.
Pogledajmo jednostavan primjer:
| SELECT model, COUNT(model) AS Qty_model, AVG(cijena) AS prosječna cijena SA PC-a GROUP BY model; |
U ovom zahtjevu se za svaki model PC-a utvrđuje njihov broj i prosječna cijena. Svi redovi sa istom vrednošću modela čine grupu, a izlaz SELECT izračunava broj vrednosti i prosečne vrednosti cene za svaku grupu. Rezultat upita bit će sljedeća tabela:
| model | Qty_model | Prosječna_cijena |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Kada bi SELECT imao stupac datuma, tada bi bilo moguće izračunati ove indikatore za svaki određeni datum. Da biste to učinili, trebate dodati datum kao kolonu za grupisanje, a zatim će se agregatne funkcije izračunati za svaku kombinaciju vrijednosti (model-datum).
Postoji nekoliko specifičnih pravila za obavljanje agregatnih funkcija:
- Ako kao rezultat zahtjeva nije primljen nijedan red(ili više od jednog reda za datu grupu), tada nema izvornih podataka za izračunavanje bilo koje od agregatnih funkcija. U ovom slučaju, rezultat funkcija COUNT će biti nula, a rezultat svih ostalih funkcija će biti NULL.
- Argument agregatna funkcija ne može sama sadržavati agregatne funkcije(funkcija od funkcije). One. u jednom upitu nemoguće je, recimo, dobiti maksimum prosječnih vrijednosti.
- Rezultat izvršavanja funkcije COUNT je cijeli broj(INTEGER). Druge agregatne funkcije nasljeđuju tipove podataka vrijednosti koje obrađuju.
- Ako funkcija SUM proizvede rezultat koji je veći od maksimalne vrijednosti tipa podataka koji se koristi, greška.
Dakle, ako zahtjev ne sadrži GROUP BY klauzule, To agregatne funkcije uključeno u SELECT klauzula, izvršavaju se na svim rezultujućim redovima upita. Ako zahtjev sadrži GROUP BY klauzula, svaki skup redova koji ima iste vrijednosti stupca ili grupe kolona navedenih u GROUP BY klauzula, čini grupu, i agregatne funkcije izvode se za svaku grupu posebno.
HAVING ponudu
Ako WHERE klauzula onda definira predikat za filtriranje redova HAVING ponudu primjenjuje nakon grupisanja definirati sličan predikat koji filtrira grupe prema vrijednostima agregatne funkcije. Ova klauzula je potrebna za validaciju vrijednosti koje su dobivene korištenjem agregatna funkcija ne iz pojedinačnih redova izvora zapisa definiranog u FROM klauzula, i od grupe takvih linija. Stoga takva provjera ne može biti sadržana u WHERE klauzula.
Da biste odredili broj zapisa u MySQL tabeli, morate koristiti posebnu funkciju COUNT().
Funkcija COUNT() vraća broj zapisa u tabeli koji odgovaraju datom kriterijumu.
Funkcija COUNT(expr) uvijek broji samo one redove za koje rezultat expr NIJE NULL.
Izuzetak od ovog pravila je kada koristite funkciju COUNT() sa zvjezdicom kao argumentom - COUNT(*). U ovom slučaju se broje svi redovi, bez obzira da li su NULL ili NOT NULL.
Na primjer, funkcija COUNT(*) vraća ukupan broj zapisa u tabeli:
SELECT COUNT(*) FROM table_name
Kako izbrojati broj zapisa i prikazati ih na ekranu
Primjer PHP+MySQL koda za brojanje i prikaz ukupnog broja redova:
$res = mysql_query("SELECT COUNT(*) FROM table_name") $row = mysql_fetch_row($res); $ukupno = $red; // ukupni zapisi echo $total; ?>
Ovaj primjer ilustrira najjednostavniju upotrebu funkcije COUNT(). Ali pomoću ove funkcije možete obavljati i druge zadatke.
Navođenjem određene kolone tablice kao parametra, funkcija COUNT(ime_stupca) vraća broj zapisa u toj koloni koji ne sadrže NULL vrijednost. Zapisi sa NULL vrijednostima se zanemaruju.
SELECT COUNT(ime_kolone) IZ ime_tablice
Funkcija mysql_num_rows() se ne može koristiti jer da biste saznali ukupan broj zapisa, potrebno je pokrenuti upit SELECT * FROM db, odnosno dobiti sve zapise, a to nije poželjno, pa je poželjno koristite funkciju brojanja.
$result = mysql_query("SELECT COUNT (*) as rec FROM db");
Korištenje funkcije COUNT() kao primjer
Evo još jednog primjera korištenja funkcije COUNT(). Recimo da postoji tabela ice_cream sa katalogom sladoleda, koji sadrži identifikatore kategorija i nazive sladoleda.