Aprēķini sql. SQL apkopotās funkcijas — SUM, MIN, MAX, AVG, COUNT Funkcijas COUNT() izmantošana ar piemēru
Man ir šāds pieprasījums:
SELECT i.*, COUNT(*) AS valūtas, SUM(ig.quantity) AS kopā, SUM(g.cena * ig.quantity) AS cena, c.īsi AS cname FROM invoice AS i, invoice_goods AS ig, good g LEFT JOIN valūta c ON (c.id = g.currency) WHERE ig.invoice_id = i.id UN g.id = ig.good_id GROUP BY BY g.currency ORDER BY i.date DESC;
tie. tiek izvēlēts pasūtījumu saraksts, kurā tiek aprēķinātas kopējās preču izmaksas dažādās valūtās (precei tiek iestatīta valūta, rezultāta ailē cname ir valūtas nosaukums)
Valūtu rezultātu kolonnā jāiegūst ierakstu skaits ar vienādu i.id, tomēr eksperimenti ar parametriem COUNT() neko nedeva - tas vienmēr atgriež 1
Jautājums: Vai valūtu kolonnā ir iespējams iegūt patieso vērtību? Tie. ja preces tiek pasūtītas ar cenām 3 dažādās valūtās, valūtas=3 ?
Tomēr MySQL ir pārāk daudz brīvību attiecībā uz SQL. Piemēram, ko nozīmē i.* šīs atlases kontekstā? Visas rēķinu tabulas kolonnas? Tā kā uz tiem neattiecas neviena grupas funkcija, būtu jauki, ja tie būtu uzskaitīti GROUP BY, pretējā gadījumā rindu grupēšanas princips nav līdz galam skaidrs. Ja jums ir jāsaņem visas preces visiem pasūtījumiem pēc valūtas, tā ir viena lieta, ja jums ir jāsaņem visas preces sagrupētas pēc valūtas katram pasūtījumam, tas ir pilnīgi atšķirīgs.
Pamatojoties uz jūsu atlasi, mēs varam pieņemt šādu datu struktūru:
Rēķinu tabula:
Invoice_goods tabula:
Preču tabula:
Valūtu tabula:
Ko jūsu pašreizējā izlase atgriezīs? Teorētiski tas atgriezīs N rindas katram pasūtījumam katrai valūtai, kurā šajā pasūtījumā ir ietvertas preces. Bet tāpēc, ka grupā by nav norādīts nekas cits kā g.currency, tas nav acīmredzami :), turklāt c.briefly kolonna arī veicina netiešu grupu veidošanos. Rezultātā katrai unikālajai kombinācijai i.*, g.currency un c.īsumā tiks izveidota grupa, kuras rindām tiks lietotas funkcijas SUM un COUNT. Tas, ka spēlēšanas rezultātā ar parametru COUNT vienmēr ieguva 1, nozīmē, ka iegūtajā grupā bija tikai viens ieraksts (t.i., grupas nav izveidotas tā, kā jums varētu būt nepieciešams, vai varat sīkāk aprakstīt prasības?). No jūsu jautājuma nav skaidrs, ko jūs vēlētos uzzināt – cik dažādas valūtas bija iesaistītas pasūtījumā vai cik pasūtījumu bija noteiktā valūtā? Pirmajā gadījumā ir iespējamas vairākas iespējas, tas viss ir atkarīgs no MySQL iespējām, otrajā ir jāraksta atlases izteiksme.
Tomēr MySQL ir pārāk daudz brīvību attiecībā uz SQL. Piemēram, ko nozīmē i.* šīs atlases kontekstā? Visas rēķinu tabulas kolonnas?
Jā tieši tā. Bet tas nespēlē lielu lomu, jo... Šajā gadījumā starp tām nav nevienas noderīgas kolonnas. Lai i.* ir i.id . Lai būtu konkrēti.
Ko jūsu pašreizējā izlase atgriezīs? Teorētiski tas atgriezīs N rindas katram pasūtījumam katrai valūtai, kurā šajā pasūtījumā ir ietvertas preces. Bet tā kā grupa pēc nenorāda neko citu kā tikai g.currency, tas nav acīmredzami :),
Tieši tā.
Tas atgriezīs tālāk norādīto (šajā piemērā no i es atlasu tikai id , nevis visas kolonnas):
| id | valūtas | Kopā | cena | cname |
|---|---|---|---|---|
| 33 | 1 | 1.00 | 198.00 | B.F. |
| 33 | 1 | 4.00 | 1548.04 | RUB |
Turklāt sleja c.īsi veicina arī netiešu grupu veidošanos.
Kā? Tabulas ir savienotas ar c.id=g.currency un grupētas pēc g.currency .
Tas, ka spēlējot ar parametru COUNT jūs vienmēr ieguvāt 1, nozīmē, ka iegūtajā grupā bija tikai viens ieraksts
Nē, grupa tika veidota no 1 ieraksti. Cik es to saprotu, šī iemesla dēļ COUNT() atgriež 1 (galu galā kolonnas, kas grupā ir atšķirīgas (lai gan, izņemot valūtas kolonnu), tiek izveidotas, izmantojot apkopošanas funkcijas).
(t.i., grupas netiek veidotas tā, kā jūs varētu prasīt, vai varat sīkāk aprakstīt prasības?).
Grupas tiek veidotas pēc nepieciešamības, katra grupa -Šis kopējās preču izmaksas katrā valūtā. Tomēr papildus tam I jārēķina cik vai elementi iekšāšis grupai.
No jūsu jautājuma nav skaidrs, ko jūs vēlētos uzzināt – cik dažādas valūtas bija iesaistītas pasūtījumā vai cik pasūtījumu bija noteiktā valūtā?
Jā, es nopelnīju nedaudz naudas. Tikai pirmais.
dmig [dokumentācija]
Ar "netiešo" dalību grupas veidošanā es domāju, ka, ja kolonna nav norādīta GROUP BY, un tajā pašā laikā NAV arguments grupas funkcijai, atlases rezultāts būs identisks kas tas būtu, ja šī kolonna BŪTU norādīta GROUP BY. Jūsu atlase un tālāk esošā atlase radīs tieši tādu pašu rezultātu (nepievērsiet uzmanību savienojumiem, es tos vienkārši izveidoju vienā ierakstīšanas formātā):
Atlasiet i.id id, count(*) valūtas, summa(ig.quantity) kopējo summu, SUM(g.cena * ig.quantity) cenu, c.īsi cname NO rēķina es pievienojos invoice_goods ig on (ig.invoice_id = i. id) pievienojiet preču g on (g.id = ig.good_id) LEFT OUTTER JOIN valūtu c ON (c.id = g.currency) grupai pēc i.id, c.īsi
Izrādās, ka katrā iegūtā izlases rindā ir viena un tikai viena valūta (ja tā būtu atšķirīga, tad būtu divas rindas). Par kādu elementu skaitu mēs runājam šajā gadījumā? Par preču pasūtīšanu? Tad jūsu izvēle ir pilnīgi pareiza, tikai šai valūtai šajā pasūtījumā ir tikai viena prece.
Apskatīsim datu shēmu:
- Vienā pasūtījumā ir daudz preču (rindu), vai ne?
- Katra prece ir prece preču katalogā, vai ne?
- Katram produktam ir noteikta (un tikai viena) valūta. Tas izriet no c.id = g.currency, vai ne?
Cik valūtas ir pasūtījumā? Tajā ir tikpat daudz punktu ar DAŽĀDĀM valūtām.
Pievienojot g.price * ig.quantity ir jēga tikai par punktiem vienā valūtā;) (lai gan var pievienot arī kilometrus ar stundām :) Kas tad jums neder!? Jūs norādāt, ka jums ir nepieciešams, cik dažādu valūtu bija iesaistītas pasūtījumā
un šajā gadījumā to darīt vienas un tās pašas atlases ietvaros bez visādiem trikiem (ko MySQL visdrīzāk nedarīs) neizdosies;(
Diemžēl es neesmu MySQL eksperts. Programmā Oracle to var izdarīt ar vienu atlasi, taču vai šis padoms jums palīdzēs? Diez vai ;)
# Vienā pasūtījumā ir daudz preču (rindu), vai ne?
# Katra prece ir prece preču katalogā, vai ne?
# Katram produktam ir noteikta (un tikai viena) valūta, tas izriet no c.id = g.currency, vai ne?
Tātad.
Viens pasūtījums: viens ieraksts rēķinu tabulā, tas atbilst n(>0) ierakstiem invoice_goods, no kuriem katrs atbilst 1 ierakstam preču tabulā, kurā ieraksts “valūta” katrā no tiem, savukārt, atbilst 1. ieraksts valūtu tabulā ( LEFT JOIN - ja rediģējat valūtu direktoriju ar greizām rokām - tādas tabulas kā MyISAM neatbalsta ārējās atslēgas).
Cik valūtas ir pasūtījumā? Tajā ir tikpat daudz punktu ar DAŽĀDĀM valūtām.
Jā tieši tā.
Pievienojot g.price * ig.quantity ir jēga tikai par punktiem vienā valūtā;) (lai gan var pievienot arī kilometrus ar stundām :)
Tāpēc grupēšana tiek veikta pēc valūtas ID (g.currency).
Programmā Oracle to var izdarīt ar vienu atlasi, taču vai šis padoms jums palīdzēs?
M.b.
Es nedaudz runāju ar Oracle un esmu pazīstams ar pl/sql.
Variants #1.
Atlasiet a.*, saskaitiet (*) (sadalīt pēc a.id) valūtām no (atlasiet i.id id, summa(ig.quantity) total, SUM(g.price * ig.quantity) cena, c.īsi cname NO rēķina es pievienojos invoice_goods ig on (ig.invoice_id = i.id) pievienojos Good g on (g.id = ig.good_id) LEFT OUTTER JOIN valūta c ON (c.id = g.currency) grupai pēc i.id, c.īsi) a
Tas izmanto tā saukto analītiskā funkcija. Ar 99% varbūtību tas nedarbojas MySQL.
Variants #2.
Tiek izveidota funkcija, piemēram, countCurrencies, kas, pamatojoties uz pasūtījuma ID, atgriež tajā piedalījušos valūtu skaitu un pēc tam:
Atlasiet i.id id, countCurrencies(i.id) valūtas, summa(ig.quantity) kopējo summu, SUM(g.cena * ig.quantity) cenu, c.īsi cname NO rēķina es pievienojos invoice_goods ig on (ig.invoice_id = i.id) pievienojiet preču g on (g.id = ig.good_id) LEFT OUTTER JOIN valūtu c ON (c.id = g.currency) grupai pēc i.id, c. īsi, countCurrencies(i.id)
Tas var darboties... bet tas tiks izsaukts katrai katra pasūtījuma valūtai. Es nezinu, vai MySQL ļauj veikt GROUP BY pēc funkcijas...
Variants Nr.3
Atlasiet i.id id, agr.cnt valūtas, summa(ig.quantity) kopējo summu, SUM(g.cena * ig.quantity) cenu, c.īsi cname NO rēķina es pievienojos rēķinam_preces ig on (ig.invoice_id = i.id ) pievienoties good go on (g.id = ig.good_id) LEFT OUTTER JOIN valūta c ON (c.id = g.currency) kreisā ārējā savienošana (atlasiet ii.id, count (atšķirīga gg.currency) cnt no rēķina ii, invoce_goods iig, good gg kur ii.id = iig.invoice_id un gg.id = iig.good_id grupa pēc ii.id) agr on (i.id = agr.id) grupa pēc i.id, c. īsi, agr. cnt
Iespējams, vispareizākā... un, iespējams, visdarbīgākā iespēja no visiem.
Ātrākais ir variants Nr.1. Nr.2 ir visneefektīvākā, jo Jo vairāk valūtu pasūtījumā, jo biežāk tās tiek skaitītas.
Nr.3 arī principā nav labākais ātruma ziņā, bet vismaz var paļauties uz kešatmiņu DBVS iekšienē.
Visu trīs atlases rezultāts būs šāds:
| id | valūtas | Kopā | cena | cname | ||||
|---|---|---|---|---|---|---|---|---|
| 33 | 2 | 1.00 | 198.00 | B.F. | ||||
| 33 | 2 | 4.00 | 1548.04 | RUB | ||||
vienam un tam pašam ID numurs valūtu kolonnā vienmēr būs vienāds, vai tas ir tas, kas jums nepieciešams?
SQL — 8. nodarbība. Ierakstu grupēšana un funkcija COUNT().
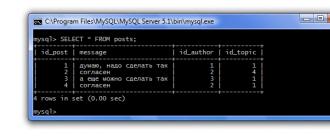
Atcerēsimies, kādi vēstījumi un kādās tēmās mums ir. Lai to izdarītu, varat izmantot parasto vaicājumu:
Ko darīt, ja mums vienkārši jānoskaidro, cik daudz ziņojumu ir forumā. Lai to izdarītu, varat izmantot iebūvēto funkciju COUNT(). Šī funkcija uzskaita rindu skaitu. Turklāt, ja * tiek izmantots kā arguments šai funkcijai, tad tiek skaitītas visas tabulas rindas. Un, ja kolonnas nosaukums ir norādīts kā arguments, tad tiek skaitītas tikai tās rindas, kurām ir vērtība norādītajā kolonnā.
Mūsu piemērā abi argumenti dos vienādu rezultātu, jo visas tabulas kolonnas NAV NULL. Uzrakstīsim vaicājumu, izmantojot sleju id_topic kā argumentu:
ATLASĪT COUNT(id_topic) NO ziņas;

Tātad, mūsu tēmās ir 4 ziņojumi. Bet ko darīt, ja mēs vēlamies uzzināt, cik ziņojumu ir katrā tēmā. Lai to izdarītu, mums būs jāsagrupē ziņojumi pēc tēmas un jāaprēķina katras grupas ziņojumu skaits. Lai grupētu SQL, izmantojiet operatoru GROUP BY. Mūsu pieprasījums tagad izskatīsies šādi:
SELECT id_topic, COUNT(id_topic) NO ziņām GROUP BY id_topic;
Operators GROUP BY liek DBVS grupēt datus pēc kolonnas id_topic (t.i., katra tēma ir atsevišķa grupa) un saskaitīt katras grupas rindu skaitu:

Nu, tēmā ar id=1 mums ir 3 ziņojumi, bet ar id=4 - viens. Starp citu, ja laukā id_topic būtu iespējamas trūkstošās vērtības, tad šādas rindas tiktu apvienotas atsevišķā grupā ar vērtību NULL.
Pieņemsim, ka mūs interesē tikai tās grupas, kurām ir vairāk nekā divi ziņojumi. Parastā vaicājumā mēs norādām nosacījumu, izmantojot operatoru KUR, taču šis operators var strādāt tikai ar virknēm, un grupām tās pašas funkcijas veic operators ŅEMOT:
ATLASĪT id_topic, COUNT(id_topic) NO ziņām GROUP BY id_topic IR SKAITS(id_topic) > 2;
Rezultātā mums ir:

4. nodarbībā apskatījām, kādus nosacījumus var uzstādīt operators KUR, tādus pašus nosacījumus var norādīt operators ŅEMOT, jums tas tikai jāatceras KUR filtri virknes un ŅEMOT- grupas.
Tāpēc šodien mēs uzzinājām, kā izveidot grupas un kā saskaitīt rindu skaitu tabulā un grupās. Vispār kopā ar operatoru GROUP BY Varat izmantot citas iebūvētās funkcijas, taču mēs tās izpētīsim vēlāk.
Šajā apmācībā jūs uzzināsit, kā lietot Funkcija COUNT SQL Server (Transact-SQL) ar sintaksi un piemēriem.
Apraksts
SQL serverī (Transact-SQL) Funkcija COUNT atgriež lauka vai izteiksmes rindu skaitu rezultātu kopā.
Sintakse
Funkcijas COUNT sintakse SQL Server (Transact-SQL) ir:
VAI funkcijas COUNT sintakse, grupējot vienas vai vairāku kolonnu rezultātus, ir:
Parametri vai argumenti
izteiksme1 , izteiksme2 , … izteiksme_n
Izteiksmes, kas nav ietvertas funkcijā COUNT un ir jāiekļauj klauzulā GROUP BY SQL priekšraksta beigās.
aggregate_expression ir kolonna vai izteiksme, kuras vērtības, kas nav NULL, tiks skaitītas.
tabulas - tabulas, no kurām vēlaties iegūt ierakstus. Klauzulā FROM ir jābūt vismaz vienai tabulai.
KUR nosacījumi - pēc izvēles. Šie ir nosacījumi, kas jāievēro atlasītajiem ierakstiem.
Ieskaitot vērtības, kas nav NULL
Ne visi to saprot, taču funkcija COUNT uzskaitīs tikai tos ierakstus, kuros izteiksmes vērtība COUNT (agregate_expression) nav NULL. Ja izteiksmē ir NULL vērtība, tā netiek iekļauta COUNT skaitītājā.
Apskatīsim funkcijas COUNT piemēru, kas parāda, kā funkcija COUNT novērtē NULL vērtības.
Piemēram, ja jums ir šāda tabula ar nosaukumu tirgi:
Šis COUNT piemērs atgriezīs 3, jo visas tirgus_id vērtības vaicājuma rezultātu kopā NAV NULL.
Tomēr, ja izpildījāt šādu SELECT priekšrakstu, kurā tiek izmantota funkcija COUNT:
Transact-SQL
SELECT COUNT(filials) NO tirgiem; -- Rezultāts: 1
Šajā COUNT piemērā tiks atgriezta tikai 1, jo tikai viena filials vērtība vaicājuma rezultātu kopā NAV NULL. Šī būs pirmā rindiņa, kurā teikts filials = "jā". Šī ir vienīgā rinda, kas ir iekļauta funkcijas COUNT aprēķinā.
Pieteikums
Funkciju COUNT var izmantot šādās SQL Server (Transact-SQL) versijās:
SQL Server vNext, SQL Server 2016, SQL Server 2015, SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Piemērs ar vienu lauku
Apskatīsim dažus SQL Server COUNT funkciju piemērus, lai saprastu, kā izmantot funkciju COUNT SQL Server (Transact-SQL).
Piemēram, varat uzzināt, cik kontaktu ir lietotājam ar last_name = "Rasputin".
Šajā funkcijas COUNT piemērā mēs norādījām aizstājvārdu “Kontaktpersonu skaits” izteiksmei COUNT (*). Tāpēc rezultātu kopa kā lauka nosaukums parādīs "Kontaktpersonu skaits".
Piemērs, izmantojot DISTINCT
Funkcijā COUNT varat izmantot operatoru DISTINCT. Piemēram, tālāk sniegtais SQL priekšraksts atgriež unikālo nodaļu skaitu, kurās vismaz vienam darbiniekam ir first_name = 'Samvel'.
Kā es varu uzzināt konkrēta piegādātāja ražoto datoru modeļu skaitu? Kā noteikt vidējo cenu datoriem ar vienādiem tehniskajiem parametriem? Uz šiem un daudziem citiem jautājumiem, kas saistīti ar kādu statistikas informāciju, var atbildēt, izmantojot galīgās (agregētās) funkcijas. Standarts nodrošina šādas apkopotas funkcijas:
Visas šīs funkcijas atgriež vienu vērtību. Tajā pašā laikā funkcijas COUNT, MIN Un MAX piemērojams jebkuram datu tipam, kamēr SUMMA Un AVG tiek izmantoti tikai ciparu laukiem. Atšķirība starp funkciju COUNT(*) Un COUNT(<имя поля>) ir tas, ka otrais, aprēķinot, neņem vērā NULL vērtības.
Piemērs. Atrodiet minimālo un maksimālo cenu personālajiem datoriem:
Piemērs. Atrodiet pieejamo ražotāja A ražoto datoru skaitu:
Piemērs. Ja mūs interesē ražotāja A ražoto dažādu modeļu skaits, tad vaicājumu var formulēt šādi (izmantojot to, ka Preču tabulā katrs modelis tiek ierakstīts vienu reizi):
Piemērs. Atrodiet pieejamo dažādu ražotāju A ražoto modeļu skaitu. Vaicājums ir līdzīgs iepriekšējam, kurā bija jānosaka kopējais ražotāja A ražoto modeļu skaits. Šeit arī jāatrod dažādu modeļu skaits datora galds (t.i., tie, kas pieejami pārdošanai).
Lai nodrošinātu, ka, iegūstot statistiskos rādītājus, tiek izmantotas tikai unikālas vērtības, kad agregātu funkciju arguments Var izmantot DISTINCT parametrs. Cits parametrs VISI ir noklusējuma un pieņem, ka tiek ieskaitītas visas kolonnā atgrieztās vērtības. operators,
Ja mums ir nepieciešams iegūt saražoto datoru modeļu skaitu visi ražotājs, jums būs jāizmanto GROUP BY klauzula, sintaktiski seko KUR klauzulas.
GROUP BY klauzula
GROUP BY klauzula izmanto, lai definētu izvades virkņu grupas, kurām var lietot apkopotās funkcijas (COUNT, MIN, MAX, AVG un SUM). Ja šīs klauzulas trūkst un tiek izmantotas apkopotās funkcijas, tad visas kolonnas ar nosaukumiem, kas minēti ATLASĪT, jāiekļauj agregētās funkcijas, un šīs funkcijas tiks lietotas visai rindu kopai, kas atbilst vaicājuma predikātam. Pretējā gadījumā visas saraksta SELECT kolonnas nav iekļauts ir jānorāda apkopotās funkcijas klauzulā GROUP BY. Rezultātā visas izvades vaicājuma rindas tiek sadalītas grupās, kuras raksturo vienādas vērtību kombinācijas šajās kolonnās. Pēc tam katrai grupai tiks piemērotas apkopotās funkcijas. Lūdzu, ņemiet vērā, ka GROUP BY visas NULL vērtības tiek uzskatītas par vienādām, t.i. grupējot pēc lauka, kurā ir NULL vērtības, visas šādas rindas tiks iekļautas vienā grupā.Ja ja ir klauzula GROUP BY, klauzulā SELECT nav apkopotu funkciju, tad vaicājums vienkārši atgriezīs vienu rindu no katras grupas. Šo līdzekli kopā ar DISTINCT atslēgvārdu var izmantot, lai rezultātu kopā novērstu dublētās rindas.
Apskatīsim vienkāršu piemēru:
| ATLASĪT modeli, COUNT(modelis) AS Daudzums_modelis, AVG(cena) AS Vidējā_cena NO PC GROUP BY modeļa; |
Šajā pieprasījumā katram datora modelim ir noteikts to skaits un vidējās izmaksas. Visas rindas ar vienādu modeļa vērtību veido grupu, un SELECT izvade aprēķina vērtību skaitu un vidējās cenas vērtības katrai grupai. Vaicājuma rezultāts būs šāda tabula:
| modelis | Daudzuma_modelis | Vidējā_cena |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Ja SELECT būtu datuma kolonna, tad šos rādītājus būtu iespējams aprēķināt katram konkrētajam datumam. Lai to izdarītu, jums ir jāpievieno datums kā grupēšanas kolonna, un pēc tam katrai vērtību kombinācijai (modelis-datums) tiks aprēķinātas apkopotās funkcijas.
Ir vairāki specifiski agregātu funkciju veikšanas noteikumi:
- Ja pieprasījuma rezultātā nav saņemta neviena rinda(vai vairāk nekā viena rinda konkrētai grupai), tad nav avota datu nevienas apkopotās funkcijas aprēķināšanai. Šajā gadījumā funkciju COUNT rezultāts būs nulle, bet visu pārējo funkciju rezultāts būs NULL.
- Arguments agregāta funkcija pati nevar saturēt apkopotas funkcijas(funkcija no funkcijas). Tie. vienā vaicājumā nav iespējams, teiksim, iegūt vidējo vērtību maksimumu.
- Funkcijas COUNT izpildes rezultāts ir vesels skaitlis(VESELS SKAITLIS). Citas apkopotās funkcijas manto to apstrādāto vērtību datu tipus.
- Ja funkcija SUM rada rezultātu, kas ir lielāks par izmantotā datu tipa maksimālo vērtību, kļūda.
Tātad, ja pieprasījums nesatur GROUP BY klauzulas, Tas agregētās funkcijas iekļauts SELECT klauzula, tiek izpildītas visās iegūtajās vaicājuma rindās. Ja pieprasījums satur GROUP BY klauzula, katra rindu kopa, kurai ir vienādas kolonnas vai kolonnu grupas vērtības, kas norādītas GROUP BY klauzula, veido grupu, un agregētās funkcijas tiek veiktas katrai grupai atsevišķi.
IR piedāvājums
Ja KUR klauzula definē predikātu rindu filtrēšanai, tad IR piedāvājums attiecas pēc grupēšanas lai definētu līdzīgu predikātu, kas filtrē grupas pēc vērtībām agregētās funkcijas. Šī klauzula ir nepieciešama, lai apstiprinātu vērtības, kas iegūtas, izmantojot agregāta funkcija nevis no atsevišķām ieraksta avota rindām, kas definētas NO klauzulas, un no šādu līniju grupas. Tāpēc šādu čeku nevar ietvert KUR klauzula.
Lai noteiktu ierakstu skaitu MySQL tabulā, jāizmanto īpašā COUNT() funkcija.
Funkcija COUNT() atgriež ierakstu skaitu tabulā, kas atbilst noteiktam kritērijam.
Funkcija COUNT(expr) vienmēr saskaita tikai tās rindas, kurām izteiksmes rezultāts NAV NULL.
Izņēmums šim noteikumam ir, ja tiek izmantota funkcija COUNT() ar zvaigznīti kā argumentu - COUNT(*) . Šajā gadījumā tiek skaitītas visas rindas neatkarīgi no tā, vai tās ir NULL vai NOT NULL.
Piemēram, funkcija COUNT(*) atgriež kopējo ierakstu skaitu tabulā:
SELECT COUNT(*) NO tabulas_nosaukums
Kā saskaitīt ierakstu skaitu un parādīt tos ekrānā
PHP+MySQL koda piemērs kopējā rindu skaita saskaitīšanai un parādīšanai:
$res = mysql_query("SELECT COUNT(*) FROM table_name") $row = mysql_fetch_row($res); $kopā = $rinda; // kopējie ieraksti echo $kopā; ?>
Šis piemērs ilustrē vienkāršāko funkcijas COUNT() izmantošanu. Taču, izmantojot šo funkciju, varat veikt arī citus uzdevumus.
Norādot konkrētu tabulas kolonnu kā parametru, funkcija COUNT(kolonnas_nosaukums) atgriež ierakstu skaitu šajā kolonnā, kas nesatur NULL vērtību. Ieraksti ar NULL vērtībām tiek ignorēti.
ATLASĪT COUNT(kolonnas_nosaukums) NO tabulas_nosaukums
Funkciju mysql_num_rows() nevar izmantot, jo, lai uzzinātu kopējo ierakstu skaitu, ir jāpalaiž SELECT * FROM db vaicājums, tas ir, jāiegūst visi ieraksti, un tas nav vēlams, tāpēc vēlams izmantojiet skaitīšanas funkciju.
$rezultāts = mysql_query("SELECT COUNT (*) kā rec FROM db");
Kā piemēru izmantojot funkciju COUNT().
Šeit ir vēl viens funkcijas COUNT() izmantošanas piemērs. Pieņemsim, ka ir tabula ice_cream ar saldējuma katalogu, kurā ir kategoriju identifikatori un saldējuma nosaukumi.